因为要遵守三大范式的要求,实际的开发中,数据库中会存在大量的零碎的“小”表。对于这些小表,我们常常使用
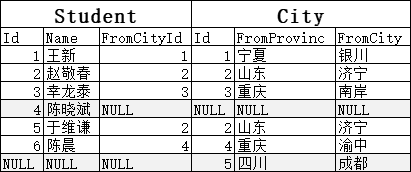
将多个表 水平 联接起来,以获取单表无法提供的信息。比如我们现在有两张表Student和City:
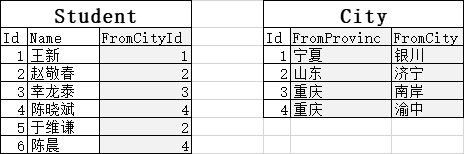
为了简化,我们只用了很少的列执行如下SQL语句:
SELECT * FROM Student s -- *指的是Join过后两张表的所有列,s是给表Student的别名 JOIN City c -- 给表City一个别名,使用JOIN将Student和City连接起来 ON s.FromCityId = c.Id -- 指定表Student(别名s)和City(别名c)连接的条件
建议:总是使用表别名。如果不使用别名,相同的列名就需要使用表的全名前缀加以区分
得到的结果就是:
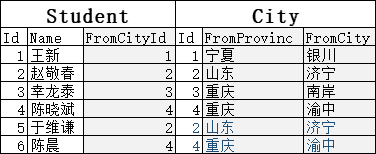
从FromCity和Id列,可以清楚的看到两表连接的方式或规则:同一行内,FromCityId的值总是等于(右边City的)Id的值。这是由SQL中:ON s.FromCityId = c.Id 决定的。意思就是:把Student的FromCityId和City的Id相等的行连接起来。
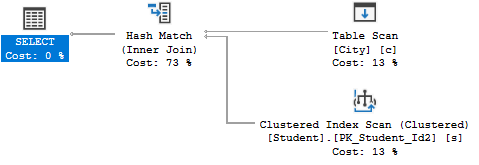
查看执行计划,可以看到SQL Server先进行了两张表的扫描,然后再进行了JOIN操作:
我们可以在SELECT子句中指定列,进一步整理显示结果,比如:
SELECT s.[Name], -- Student表的Name c.FromProvince AS Province, -- City表的FromProvince,还给一个列别名Province c.FromCity City -- City表的FromCity,还给一个列别名City FROM Student s JOIN City c ON s.FromCityId = c.Id
结果就会变成:
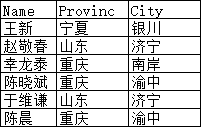
这就是SQL中默认的连接方式:
关键字 INNRE JOIN,其中INNER可以省略。演示:
关键字:OUTER,也可以省略。因为它又还细分为:
所谓“左”和“右”,是指在书写SQL语句时,在JOIN左边或右边。
为了展示左连接,我们修改一下上表数据,把“陈晓斌”的FromCityId改成NULL值。使用左连接:
SELECT * FROM Student s LEFT OUTER JOIN City c -- OUTER 可以省略 ON s.FromCityId = c.Id
因为要保证左表全部显示,“陈晓斌”就一定会被保留。但保留之后,City里没值怎么办呢?用NULL填充:
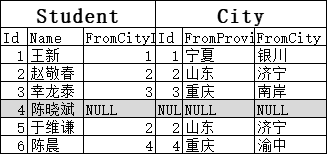
如果是内连接的话,因为NULL值不会和City.Id里的1,2,3,4相等,所以结果就会没有“陈晓斌”这一行:
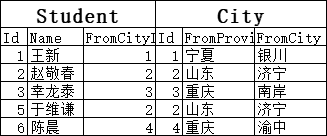
注意:没有“陈晓斌”这一行了
同理,为了展示右连接,我们可以在City表中添加一行:5/四川/成都,这个城市在Student表中没有任何对应。使用右连接:
SELECT * FROM Student s RIGHT JOIN City c -- 省略了OUTER ON s.FromCityId = c.Id
因为要保证由表全部显示,“5/四川/成都”就一定会被保留(但FromCityId=NULL的“陈晓斌”也不会保留)。保留之后,Student里没值还是用NULL填充: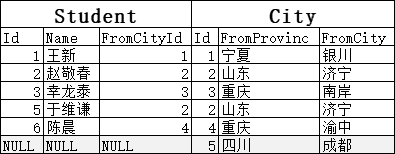
如果是内连接的话,Student表中没有任何一行FromCityId=5,所以结果就不会有“5/四川/成都”这一行:
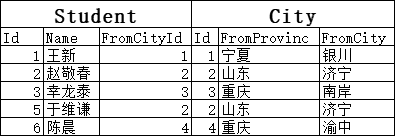
注意:没有“5/四川/成都”这一行了
@想一想@:Student LEFT JOIN City是不是等于 City LEFT JOIN Student?
那么最后,全连接就非常好理解了:
SELECT * FROM Student s FULL JOIN City c ON s.FromCityId = c.Id
结果为:
最后,我们来了解一下
SELECT * FROM Student s CROSS JOIN City c
这种连接会不进行任何过滤,依次:
这种运算方式又被称之为笛卡尔乘积。其计算结果的行数非常大。同学们了解即可,一般不需要使用。
实际上,在SELECT查询语句中,使用JOIN连接的表,可以像单表一样使用WHERE/ORDER/GROUP等操作。
演示:略
但是,注意不要
在INNER JOIN的时候,可能没有什么问题,比如这两句SQL是等效的:
SELECT * FROM Student s JOIN City c ON s.FromCityId = c.Id AND s.[Name] = N'幸龙泰' -- 使用的是ON中的AND SELECT * FROM Student s JOIN City c ON s.FromCityId = c.Id WHERE s.[Name] = N'幸龙泰' -- 注意WHERE必须在ON的后面
在外连接的时候,
使用WHERE子句结果仍然正常(符合我们的预期):
SELECT * FROM Student s LEFT JOIN City c ON s.FromCityId = c.Id WHERE s.[Name] = N'幸龙泰'
SELECT s.[Name], c.FromProvince, c.FromCity -- 为了结果清晰只显示关键字段 FROM Student s LEFT JOIN City c ON s.FromCityId = c.Id AND s.[Name] = N'幸龙泰'

整张表,包括姓名不是“幸龙泰”的同学都被查询出来了,而且我们还注意到除了“幸龙泰”,关联的City表中的值全部为NULL!这是怎么回事?
从逻辑上来讲,在ON中定义的条件是用于“连接”的,不是用于对查询结果进行过滤的。所以,根据左外连接的规则:
从而形成了上述查询结果。
另外,对比两条语句的执行计划:
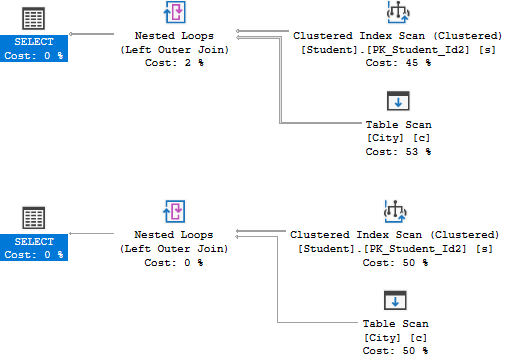
看起来都差不多。但是,把鼠标停在Student的Clustered Index Scan上,你就会发现区别:


可以看出,在Student上设置的WHERE子句其实在JOIN之前都执行了!\(^o^)/为了代码的可读性,我们推荐“两个总是”:
直接上语法,背下来就行。记忆规律就是在单表的删改语句中加了一行FROM...JOIN...ON。
比如,删除来自重庆的同学:
DELETE Student FROM Student s JOIN Address a ON s.FromCityId = a.Id WHERE s.FromProvince = N'重庆'将来自重庆的同学的成绩加5分:
UPDATE s SET Score += 5 -- 可以使用表别名s FROM Student s JOIN Address a ON s.FromCityId = a.Id WHERE s.FromProvince = N'重庆'
就像外键不仅仅用于多张表的连接一样,JOIN也不仅仅用于连接其他表,我们还可以让表自己和自己联接。
和多表连接唯一的不同:连接时必须使用表别名。(@想一想@:为什么?)
比如有这么一个需求:找到姓名重复的学生。我们就可以使用自连接:
SELECT a.Id, b.Id, a.[Name],b.[Name] FROM Student a JOIN Student b -- Student表自己和自己相连接 ON a.[Name] = b.[Name] -- “两表”连接的条件是名称相同
观察一下,姓名重复的同学自连接之后的特征是什么?如何过滤?
WHERE a.Id <> b.Id -- 如果说没有重复,就不可能出现a.Id <> b.Id
@想一想@:如何删除重复的数据(只保留一条)
可以将多个查询结构纵向联接,只要这些查询结果列的数量、顺序相同,且每一列的数据类型能够兼容(可隐式转换)。比如我们可以把学生的综合成绩和各科成绩用一个查询结果显示出来,并按学生姓名有序显示:
SELECT [Name], N'总体' ,Score FROM Student -- 在Student中补充了一列以对其 UNION -- 没有ALL,会清除重复行 SELECT [UserName], [Subject], Score FROM Exam ORDER BY [Name] -- 列名以第一个查询子句为准 --ORDER BY [UserName] -- 非第一个查询子句的列名会报错
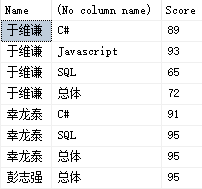
注意以下几个语法点:
多快好省!前端后端,线上线下,名师精讲
更多了解 加:

