命名空间:
using System.IO;
本身可以用字符串表示:
string path = @"c:\17bang\yz";复习:@逐字字符串
但.NET提供了一个Path静态类,可以更方便的针对文件路径(字符串,不涉及文件夹或文件本身)进行操作。
常用方法:
string subPath = Path.Join(path, @"test.text"); //.NET core独有 string subPath = Path.Combine(path, @"test.text");#体会#:为了方便,封装方法
Console.WriteLine("Path.HasExtension(subPath):" + Path.HasExtension(subPath));
Console.WriteLine("Path.GetExtension(subPath):" + Path.GetExtension(subPath));
Console.WriteLine("Path.GetFileNameWithoutExtension(subPath):" + Path.GetFileNameWithoutExtension(subPath));
Console.WriteLine("Path.ChangeExtension(subPath, \"fei\"):" + Path.ChangeExtension(subPath, "fei"));
Directory,和Path一样是静态类,常用方法:
增:CreateDirectory()删:Delete()//1、如果文件夹下还有文件,需要recursive=true,否则报错 //2、正在被使用的文件夹不会被删除,也不会报错 Directory.Delete(path, false);改:SetXXX()
//Directory.CreateDirectory(subPath); //重复创建文件夹不会报异常 if (Directory.Exists(path))
IEnumerable<string> directories = Directory.EnumerateDirectories(
path,
"*w?x", //pattern: * 任意多个字符 ? 1个任意字符
SearchOption.AllDirectories); //可以使用哦Linq操作
//直接watch会异常
foreach (var item in directories)
{
Console.WriteLine(item);
File,和Directory一样是静态类,常用方法:
增:Create() / CreateText()
删:Delete()
改:WriteXXX() / Append() / SetXXX() / Copy() / Decrypt() / Encrypt()
File.WriteAllText(subPath, "源栈欢迎你\r\n"); //不推荐 File.WriteAllText(subPath, "源栈欢迎你" + Environment.NewLine); //推荐
查:Read() / Exists() / GetXXX() / Open()
演示:ReadLines()不会立即读文件(同Linq的延迟执行)
IEnumerable<string> texts = File.ReadLines(subPath); foreach (var item in texts)#体会#:IEnumerable<T>
文件夹和文件操作都分别具有静态类/方法和实例类/方法:
@想一想@:
//每个方法都要带一个subPath参数 Directory.CreateDirectory(subPath); Directory.Delete(subPath, true); //subPath一次传入,反复使用 DirectoryInfo directoryInfo = new DirectoryInfo(subPath); directoryInfo.Create(); directoryInfo.Delete();
实例对象一般不会通过new获得,而是通过File.静态方法获得。
创建一个文件
FileStream stream = File.Create(path);
常用的属性方法
stream.Write(
new byte[4] { 33, 34, 35, 36 }, //要写入的字节
0, //偏移量,从字节数组的第几个元素开始
4 /*缓冲的大小*/);
stream.Flush();
Console.WriteLine(stream.Position);
为什么需要Position(以及offset等),因为当不能一次性的把所有字节写入文件时,需要要用它来做循环条件:
byte[] buffer = new byte[10] { 33, 34, 35, 36, 69, 70, 71, 88, 90, 91 };
int offset = 0, count = 3;
while (stream.Position < buffer.Length) //不完全正确
{
stream.Write(buffer, offset, count);
stream.Flush();
offset += count;
//Console.WriteLine(stream.Position);
}
通过OpenRead()获得一个stream流
FileStream stream = File.OpenRead(path);
然后准备一个byte[]容器
byte[] container = new byte[100];
从文本中读出一定的内容,存放到容器中
stream.Read(container, 0, 100);
将字节按一定的编码格式转换成字符串(或者其他方式处理)
Console.WriteLine(Encoding.UTF8.GetString(container));
如果仅仅是针对文本文件的读写操作,更方便的是使用:
其对象也是通过File的(Create/Append/Open)Text静态方法获得:
Create创建新文件,Append在原文件末尾添加。
StreamWriter writer = File.AppendText(path);
Write和WriteLine有多个重载方法:
writer.Write(false);
writer.WriteLine();
writer.Write(new char[] { '源', '栈' });
还需要flush()才能真正的写入文件
writer.Flush();
获取对象:
StreamReader reader = File.OpenText(path);调用(重载)方法
Console.WriteLine(reader.ReadLine()); Console.WriteLine(reader.Read()); Console.WriteLine(reader.ReadToEnd());
读写完成之后,我们应该调用Dispose()释放文件资源,让其他“人”也可以操作该文件
writer.Dispose();
为了保证无论有无异常,Dispose()都会被调用,所以Dispose()应写在finally中。
但C#提供了using(){}语法自动释放资源:
using (StreamReader reader = File.OpenText(path))
{
Console.WriteLine(reader.ReadToEnd());
}
注意:使用using的条件是resouce实现了IDisposable
演示:Student类实现了IDisposable也可以被using,反之不行
#体会#:接口的作用,对比foreach理解
总是推荐使用using,因为:
注意大量带有async的异步方法:I/O领域恰好是能够利用(无阻塞)异步提高性能最合适的地方。因为:
理解:多线程并发和IO异步区别。
需要添加dll引用 (dll:dynamic link libary):
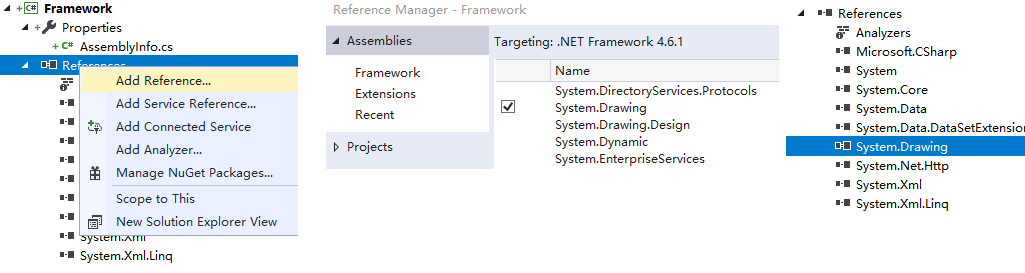
查看.csproj项目文件
<Reference Include="System.Drawing">

复习:Alt+Enter查看项目属性,确认项目使用的.NET版本
但代码都是一样一样的!
Bitmap image = new Bitmap(200, 100); //生成一个像素图“画板”
Graphics g = Graphics.FromImage(image); //在画板的基础上生成一个绘图对象
g.Clear(Color.AliceBlue); //添加底色
g.DrawLine(new Pen(Color.Black), new Point(0, 0), new Point(100, 50)); //画直线
g.DrawString("hello, luckystack", //绘制字符串
new Font("宋体", 14), //指定字体
new SolidBrush(Color.DarkRed), //绘制时使用的刷子
new PointF(5, 6) //左上角定位
);
image.SetPixel(195, 95, Color.BlueViolet); //绘制一个像素的点
image.Save(@"C:\17bang\hello.jpg", ImageFormat.Jpeg); //保存到文件p
复习/了解:网页由HTML内容构成……
最关键的就是拿到网页内容:
HttpClient client = new HttpClient();
string html = client.GetStringAsync("https://17bang.ren/Code/538").Result;
然后,就可以根据正则表达式(复习)过滤得到其中href的值:
MatchCollection matches = Regex.Matches(html, @"<a.*href=['""](?<uri>[^""^']*)");
foreach (Match match in matches)
{
Console.WriteLine(match.Groups["uri"].Value);
然后再根据这些href值拿到网页内容,不断重复上述过程……
见:J&C:文件:清理资源 / flush / 序列化 / 绘图
多快好省!前端后端,线上线下,名师精讲
更多了解 加:

