我们现在有了:
那么,如何体现出某个学生的老师是谁呢?
只需要一个在Student表上添加一列TeacherId,记录该学生的老师的Id就可以了。
如果需要查看某个学生老师的完整信息,通过他的TeacherId值,再到Teacher表中进行查找。

TeacherId据说Student表的
通常,我们都是使用主键作为外键(Foreign Key)。但是,我们也可以使用其他唯一列,或者能唯一标记行的多个列。
也就是在两张表之间建立主外键关系,比如:Student上有TeacherId外键(一个Teacher多个Student):
记忆小窍门:先有主表,才有从表,从表不能脱离主表单独存在(后文详述:级联)
但是,主外键关系也可以在同一张表中产生(面试陷阱)!比如,学生被变成了组,每个组都有一个组长,组长也是学生。
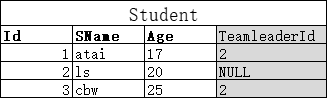
所以,外键列可以指向主表自己。
PS:和主键/主键约束(复习)经常被混用一样,外键和外键约束虽然在严格意义上讲有区别,但也一样被混用。
和主键上通常都会添加主键约束一样,外键上也会添加外键约束。
添加外键约束,可以在进行表数据操作的时候,维护表数据的完整(正确)性,即:
从表不能出现主表中没有的外键值。
对应现实:一个Student不能有一个不存在的老师。
添加外键约束的核心SQL语句:
CONSTRAINT FK_Teacher_Id -- 指定约束名称,外键建议以FK开头,后跟表和列名 FOREIGN KEY (TeacherId) -- 约束类型:外键,且外键列为TeacherId REFERENCES Teacher(Id) -- 外键表为Teacher,作为外键使用的列为Teacher上的Id
ALTER TABLE Student -- 修改表 ADD CONSTRAINT ...
CREATE TABLE Major
(
-- ...
TaughtBy INT,
CONSTRAINT FK_Teacher_Id FOREIGN KEY(TaughtBy) REFERENCES Teacher(Id)
演示:
从表上的外键列值:
外键约束的删除:
ALTER TABLE Major DROP CONSTRAINT FK_Teacher_Id
alter table Major drop foreign key FK_Teacher_Id
同样因为外键约束,我们是不能在主表上删除已被从表外键引用的行的。(或者更改使其违反外键约束)
但是,有时候,即使主键被从表引用,我们也要坚持删除主表行/更改主表主键,怎么办?
通常我们可以(事务中演示):
上述过程可由数据库自动完成,被称之为级联(cascade)。
这需要在建立外键关系时指定:(演示)
ALTER TABLE Teacher ADD CONSTRAINT FK_Teacher_Id FOREIGN KEY (TeacherId) REFERENCES Teacher(Id) ON DELETE CASCADE -- 在主表数据被删除时自动删除所有从表数据 ON UPDATE SET NULL -- 在主表主键被更新时自动设置相应从表外键值为NULL
ER模型是独立的,就是一种“对实体关系的建模”,将其归纳成:1对1、1对多和多对多,不属于任何一种语言或技术。
在面对对象的语言(复习)中,和关系数据库中有不同的实现:
关系数据可以即让两种表使用相同的Id,如下所示:

广义的1:1包含了1:0的这种情况,如上表所示,Id为3的Smith还没有妻子。
这种情形可以让Husband为主表,Id自动生成;Wife为从表,Wife表中的Id为外键,不要自动生成。
但在实际开发中,我们很少使用“一对一”的关系,而是将其变成:
可以Daddy做主表,Children做从表:
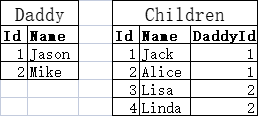
可以看出一个Daddy可以有多个Children,比如Jason的孩子是Jack和Alice。
这种方式也可以用于表示“一对一”,只需要我们在外键上添加唯一约束即可。
这时候我们无法通过在表上添加列的方式予以实现,所以我们选用新建一张“关系表”,如下图所示:
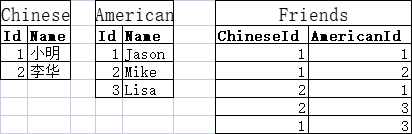
Friends这张表就是“关系表”,它仅用于记录Chinese和American之间的关系。
#常见面试题#
所谓范式,你可以理解为:规范模式,即(数据库表设计时)应该遵守的规范、应该采取的模式。
学习的关键:理解范式的目的。
要求表中的每个列都不可再分。
以下表为例:
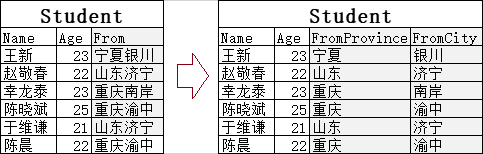
左边的表中From列,还可以被拆分成FromProvince和FromCity两列,所以它不满足于第一范式的要求。
满足第一范式,需要转换成右表。
主要是针对使用“联合主键”的场景。
要求在第一范式的基础之上,一行数据,所有非主键列都是由联合主键“整体”确定的。
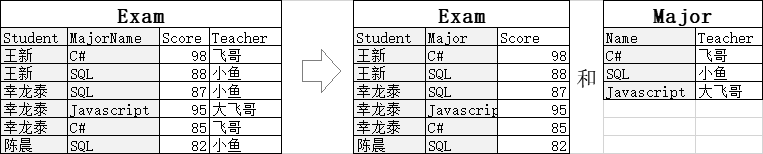
以上表为例,成绩(Score)是学生(Student)某门功课(Major)的成绩,一个学生一门功课只能有一个成绩,所以学生成绩是通过“学生和功课”两者整体确定的:这是符合第二范式的。
但是,一门功课就有一个老师(Teacher),老师是由功课直接决定的,和Student没有关系:这就违反了第二范式。
在第二范式的基础之上,确保每一个非主键列都是由唯一主键直接确定的。
比如这样一张学生表:
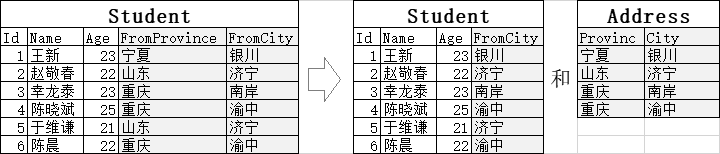
仔细分析,我们发现,学生的Name、Age、FromCity确实都是由Id确定的;但FromProvince是由FromCity确定的:这就违反了第三范式。
#体会#:满足范式的方法就是“拆”,拆分列拆分表。
满足第一范式的“拆分列”,主要是为了满足“业务需求”。
比如可能有这样的需求:统计出来自各省的同学共有多少人,在左表上就不便操作。
当然你还可能问:那右表还需不需要继续拆分呢?拆分什么时候到头?是不是要一直拆,拆成一个一个的字符?比如学生的姓和名是不是也要拆?
还是看需求。如果有按姓进行操作的需求,就要拆;没有,就不用拆。
第二第三范式“拆分表”,主要是为了消除数据冗余。
冗余的弊端非常明显:
但是有时候,因为某些特定原因(通常是提高性能),我们愿意“以空间换时间”,宁愿从单张表中立即获取数据,而不愿意多表联合查询(比如获取某学生所在省份)。这时候也使用冗余违反范式约定也是可以的!
#体会#:范式不是固定的、强制性的。
所以虽然还有第四第五……范式,但绝大部分情况,我们只要满足三大范式就足够了。
实际上,我们学习的数据库是一种“关系型(Relational)”数据库,他所依赖的理论就是关系模型。(除了关系模型,还有:层次模型/网状模型……)
这个模型最早是非常学术化的,所以有一大堆很“学术范儿”的名词:
比如第一范式要将列拆分到不可再拆分,就可以说是保证列的原子性。
还有保证数据的完整性(一致性),意思就是要保证数据:正确且符合逻辑(通常使用约束来实现),包括:
第二范式:消除 非主属性 对于 码 的 部分函数依赖
第三范式:消除 非主属性 对于 码 的 传递函数依赖。
因为要遵守三大范式的要求,实际的开发中,数据库中会存在大量的零碎的“小”表。对于这些小表,我们常常使用
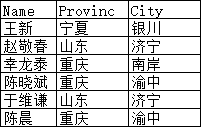
将多个表 水平 联接起来,以获取单表无法提供的信息。比如我们现在有两张表Student和City:
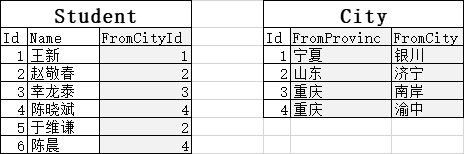
为了简化,我们只用了很少的列执行如下SQL语句:
SELECT * FROM Student s -- *指的是Join过后两张表的所有列,s是给表Student的别名 JOIN City c -- 给表City一个别名,使用JOIN将Student和City连接起来 ON s.FromCityId = c.Id -- 指定表Student(别名s)和City(别名c)连接的条件
建议:总是使用表别名。如果不使用别名,相同的列名就需要使用表的全名前缀加以区分
得到的结果就是:
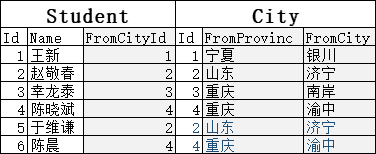
从FromCity和Id列,可以清楚的看到两表连接的方式或规则:同一行内,FromCityId的值总是等于(右边City的)Id的值。这是由SQL中:ON s.FromCityId = c.Id 决定的。意思就是:把Student的FromCityId和City的Id相等的行连接起来。
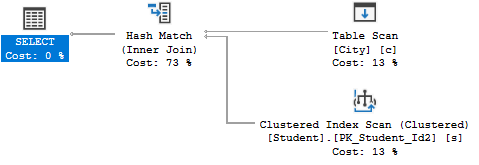
查看执行计划,可以看到SQL Server先进行了两张表的扫描,然后再进行了JOIN操作:
我们可以在SELECT子句中指定列,进一步整理显示结果,比如:
SELECT s.SName, -- Student表的Name c.FromProvince AS Province, -- City表的FromProvince,还给一个列别名Province c.FromCity City -- City表的FromCity,还给一个列别名City FROM Student s JOIN City c ON s.FromCityId = c.Id
结果就会变成:
这就是SQL中默认的连接方式:
关键字 INNRE JOIN,其中INNER可以省略。
除此以外,还有:关键字:OUTER,也可以省略。因为它又还细分为:
所谓“左”和“右”,是指在书写SQL语句时,在JOIN左边或右边。
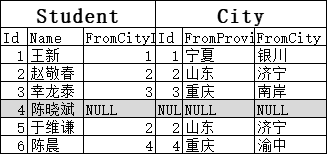
为了展示左连接,我们修改一下上表数据,把“陈晓斌”的FromCityId改成NULL值。使用左连接:
SELECT * FROM Student s LEFT OUTER JOIN City c -- OUTER 可以省略 ON s.FromCityId = c.Id
因为要保证左表全部显示,“陈晓斌”就一定会被保留。但保留之后,City里没值怎么办呢?用NULL填充:
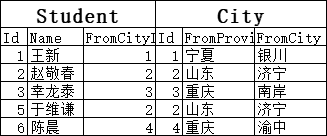
如果是内连接的话,因为NULL值不会和City.Id里的1,2,3,4相等,所以结果就会没有“陈晓斌”这一行:
同理,为了展示右连接,我们可以在City表中添加一行:5/四川/成都,这个城市在Student表中没有任何对应。使用右连接:
SELECT * FROM Student s RIGHT JOIN City c -- 省略了OUTER ON s.FromCityId = c.Id
因为要保证由表全部显示,“5/四川/成都”就一定会被保留(但FromCityId=NULL的“陈晓斌”也不会保留)。保留之后,Student里没值还是用NULL填充: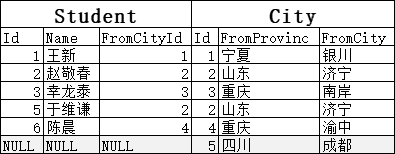
@想一想@:Student LEFT JOIN City是不是等于 City RIGHT JOIN Student?
那么最后,全连接就非常好理解了:
SELECT * FROM Student s FULL JOIN City c ON s.FromCityId = c.Id
结果为:
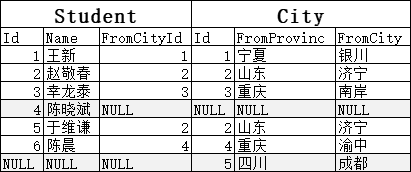
最后,我们来了解一下
SELECT * FROM Student s CROSS JOIN City c
这种连接会不进行任何过滤,依次:
这种运算方式又被称之为笛卡尔乘积。其计算结果的行数非常大。同学们了解即可,一般不需要使用。
演示:
但是,注意不要
在INNER JOIN的时候,可能没有什么问题,比如这两句SQL是等效的:
SELECT * FROM Student s JOIN City c ON s.FromCityId = c.Id AND s.SName = N'幸龙泰' -- 使用的是ON中的AND SELECT * FROM Student s JOIN City c ON s.FromCityId = c.Id WHERE s.SName = N'幸龙泰' -- 注意WHERE必须在ON的后面
在外连接的时候,
使用WHERE子句结果仍然正常(符合我们的预期):
SELECT * FROM Student s LEFT JOIN City c ON s.FromCityId = c.Id WHERE s.SName = N'幸龙泰'但使用AND的结果就变得“诡异”起来:
SELECT s.SName, c.FromProvince, c.FromCity -- 为了结果清晰只显示关键字段 FROM Student s LEFT JOIN City c ON s.FromCityId = c.Id AND s.SName = N'幸龙泰'

整张表,包括姓名不是“幸龙泰”的同学都被查询出来了,而且我们还注意到除了“幸龙泰”,关联的City表中的值全部为NULL!这是怎么回事?
从逻辑上来讲,在ON中定义的条件是用于“连接”的,不是用于对查询结果进行过滤的。所以,根据左外连接的规则:
从而形成了上述查询结果。
另外,对比两条语句的执行计划,看起来都差不多:
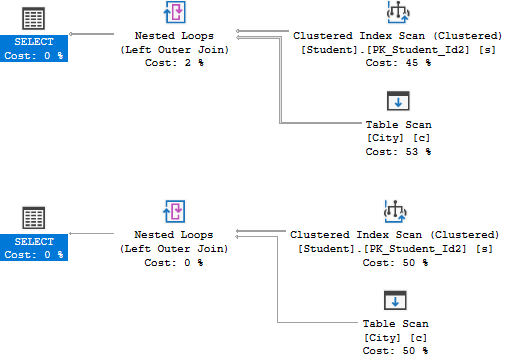
但是,把鼠标停在Student的Clustered Index Scan上,你就会发现区别:


可以看出,在Student上设置的WHERE子句其实在JOIN之前都执行了!\(^o^)/为了代码的可读性,我们推荐“两个总是”:
就像外键不仅仅用于多张表的连接一样,JOIN也不仅仅用于连接其他表,我们还可以让表自己和自己联接。
和多表连接唯一的不同:连接时必须使用表别名。(@想一想@:为什么?)
比如有这么一个需求:找到姓名重复的学生。我们就可以使用自连接:
SELECT a.Id, b.Id, a.SName,b.SName FROM Student a JOIN Student b -- Student表自己和自己相连接 ON a.SName = b.SName -- “两表”连接的条件是名称相同
观察一下,姓名重复的同学自连接之后的特征是什么?如何过滤?
WHERE a.Id <> b.Id -- 如果说没有重复,就不可能出现a.Id <> b.Id
@想一想@:如何删除重复的数据(只保留一条)
可以将多个查询结构纵向联接,只要这些查询结果列的数量、顺序相同,且每一列的数据类型能够兼容(可隐式转换)。
比如我们可以把学生的老师用一个查询结果显示出来,并按姓名有序显示:
SELECT SName, Age, 'Student' AS Roles FROM Student UNION ALL -- 没有ALL,会清除重复行 SELECT TName, Age, 'Teacher' FROM Teacher ORDER BY SName; -- 不是TName

注意以下几个语法点:
多快好省!前端后端,线上线下,名师精讲
更多了解 加:

