数组的问题:不能方便的移动/插入/删除,所以快速排序只能使用交换,增加了代码的难度。
所以我们引入链表:
一种物理存储单元上非连续、非顺序的存储结构,数据元素的逻辑顺序是通过链表中的指针链接次序实现的。链表由一系列结点(链表中每一个元素称为结点)组成,结点可以在运行时动态生成……
简单的例子:
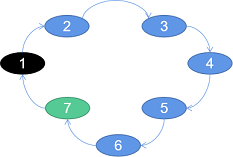
一图胜前言:

总结:链表中的每一个节点都记着它的上/下一个节点。其中:
链表的:
常用于操作系统中的内存/磁盘管理。演示:形成存储碎片 => 使用链表粘合存储空间

@想一想@:链表又有什么问题不?
按照链表中节点记录的

比如我们一起帮的文章单页,每一篇底部都有一个“上一篇”和“下一篇”:

还可以有一种特殊的环状/循环链表:头尾相连
定义了一个(头)节点,也就定义了一个链表:
class node {
constructor(value) {
//让节点中可以存放一个值,以便调试/测试用
this.value = value;
}
}
怎么让它记录下一个节点是啥呢?用属性next:
//生成2个节点 var n1 = new node(1); var n2 = new node(2); //让n1的next属性指向n2,链表成型! n1.next = n2;
@想一想@:再加一个节点怎么做?
能不能把“插入一个节点”封装成一个方法?比如:把“节点5插入2和3之间”,怎么定义?
PS:不要忘了,我们并不总是在链表末尾插入的!
首先,把“节点5插入2和3之间”转变成“节点5插入2之后(InsertAfter())”,@想一想@:为什么?因为:然后,节点5怎么传入方法(指明“把谁”插入节点2之后)?是不是要在InsertAfter()中定义两个参数?能不能有更好的方法?
应该在node类中定义这样的一个实例方法:
class node {
constructor(value) {
this.value = value;
}
insertAfter(node){
}
}
调用的话:
n5.insertAfter(n2);
insertAfter()方法的实现很简单:(复习:this)
node.next = this; // n2.next = n5; this.next = node.next; // n5.next = n2.next(n3);
@试一试@:是这样的吗?
var n1 = new node(1), n2 = new node(2), n3 = new node(3), n4 = new node(4); n1.next = n2; n2.next = n3; n3.next = n4;
var n5 = new node(5); n5.insertAfter(n2);
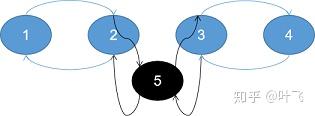
和单向链表相比,双向链表的每个节点都多记录一个之前的节点,即多一个previous属性:
n2.previous = n1; n3.previous = n2; n4.previous = n3;我们试着实现双向链表的insertAfter(),添加如下代码:
this.previous = node; //this.previous = n2; node.next.previous = this; //n3.previous = n5;
@想一想@:就这样写一写,代码质量你放心吗?
其全称是Test-DrivenDevelopment(测试驱动开发),其核心是:先测试,再开发。即在开发功能代码之前,先编写单元测试用例代码。
具体来说,它要求的开发流程是这样的:
按飞哥的定义,单元测试是开发人员自己用代码实现的测试。注意这个定义,其核心在于:
后面我们会介绍专门的单元测试工具,但现在我们先用自己的代码简单模拟一下:
其实就是把我们之前散乱书写(script块+控制台)的测试代码放在一个专门的方法当中,然后用console.log()输出被测试方法运行过后预期值(expected)和实际值(actual)是否一致,模拟断言(Assert):
function insert5After2Test(){
setup();
//之前写在控制台
var n5 = new node(5);
n5.insertAfter(n2);
//1 2 [5] 3 4
console.log(n2.next == n5); //true:符合预期,方法OK;否则,有问题
console.log(n5.next == n3);
console.log(n3.previous == n5);
console.log(n5.previous == n2);
//可以一目了然的看出方法运行之后的结果是否符合预期
tearDown();
}
这样的一个方法就被称之为一个测试用例(test case)。
注意其中的:
会在每一个测试用例执行前后调用,用于设置和清理测试环境,这里就是建立n1-n2-n3-n4构成的双向链表:
//全局变量,公用 var n1, n2, n3, n4;
function setup(){
n1 = new node(1); //每次都重新生成全新的对象
n2 = new node(2);
n3 = new node(3);
n4 = new node(4);
n1.next = n2; //将对象串起来
n2.previous = n1;
n2.next = n3;
n3.previous = n2;
n3.next = n4;
n4.previous = n3;
}
TearDown()在这里暂时没用,所以就是一个空方法。复杂测试环境可以做一些释放文件资源/数据库连接之类的工作。

继续在InsertAfterTest()中添加Assert行
var n6 = new node(6); n6.insertAfter(n4); //1 2 5 3 4 [6] console.log(n4.next == n6); console.log(n6.next == undefined); //可省略也可以保留 console.log(n6.previous == n4);演示:测试无法通过,报异常
@笑一笑@:
一个测试工程师走进一家酒吧,要了一杯啤酒
一个测试工程师走进一家酒吧,要了一杯咖啡;
一个测试工程师走进一家酒吧,要了0.7杯啤酒;
一个测试工程师走进一家酒吧,要了-1杯啤酒;
一个测试工程师走进一家酒吧,要了2^32杯啤酒;
一个测试工程师走进一家酒吧,要了一杯洗脚水;
一个测试工程师走进一家酒吧,要了一杯蜥蜴;
一个测试工程师走进一家酒吧,要了一份asdfQwer@24dg!&*(@;
一个测试工程师走进一家酒吧,什么也没要;
一个测试工程师走进一家酒吧,又走出去又从窗户进来又从后门出去从下水道钻进来;
一个测试工程师走进一家酒吧,又走出去又进来又出去又进来又出去,最后在外面把老板打了一顿;
一个测试工程师走进一家酒吧,要了一杯烫烫烫的锟斤拷;
一个测试工程师走进一家酒吧,要了NaN杯Null;
一个测试工程师冲进一家酒吧,要了500T啤酒咖啡洗脚水野猫狼牙棒奶茶;
一个测试工程师把酒吧拆了;
一个测试工程师化装成老板走进一家酒吧,要了500杯啤酒并且不付钱;
一万个测试工程师在酒吧门外呼啸而过;
一个测试工程师走进一家酒吧,要了一杯啤酒';DROP TABLE 酒吧;
测试工程师们满意地离开了酒吧。
然后一名顾客点了一份炒饭,酒吧炸了。
@想一想@:关于InsertAfter(),还有什么我们没有想到的不?
修改我们的开发代码:
//引入分支
if(node.next == undefined){
//1 2 5 3 4 [6] //n6.insertAfter(n4); //this:n6; node:n4 node.next = this; this.previous = node;再跑一下测试……
再看一下我们的代码,有没有发现一些可以优化的地方?比如,应该拆成两个测试方法:
insert5After2Test(); insert6After4Test();
其实飞哥之前给同学们进行作业点评。如果你的代码没有错误,但我还是给你改了,这就是在做重构(refactor):
在不改变代码运行结果的前提下,优化代码质量(安全、性能和可读性)。
不知道大家有没有听说过一句话:
好代码都是改出来的。
很少有人一次性的写出非常完美的代码——尤其是代码会随着业务逻辑不断变化的时候,你根本就不可能一次性的完成代码,一定是不断的修修补补。
但是,实际开发中,你会发现“修修补补”就会把代码慢慢地变成了“祖传屎山”。最有越改越烂,哪有什么“千锤百炼”?!
可以想象的一个场景:你满怀激情地正准备要重构,被你项目经理一把扑倒在地,“小子,不要命啦!?”
为什么?
代码之间是相互“耦合”的,所以“牵一发而动全身”,完全有可能形成“多米诺骨牌效应”,一改就崩。
比如,原开发代码insertAfter()的分支中就有重复代码,能将他们抽出分支么?
node.next = this;
this.previous = node;
if(node.next != undefined){
this.next = node.next;
// this.previous = node; //if...else里都有,所以……
node.next.previous = this;
// node.next = this;
}
从逻辑上看,好像没有问题?确定不确定?你懵了……
这就是为什么不能/不敢/不愿重构的原因:
如果没有单元测试保障的话。
其实添加新的feature(功能),修复旧的bug也一样,很容易对其他代码产生干扰,引入新的bug。而且这些bug可能很隐蔽,不一定能够被及时发现——除非你有单元测试。
有了单元测试,每次代码改动,把所有的(注意,是所有的!)单元测试跑一遍,都跑过了,就证明改动没有影响现有代码。
#常见面试题:你如何看待TDD?
优势
因为要先写单元测试再写开发代码,所以所有的开发代码都有对应的单元测试(这被称之为100%的代码测试覆盖率),于是单元测试保证了代码的:
一个项目,开发所需的时间要占20%,而维护的时间要占80%同学们进入工作岗位,更大概率也是进行代码的维护工作(添加新feature,修复老bug等),而不是从头开发。如果没有单元测试覆盖,很多时候维护工作就是“头疼医头脚疼医脚”,修复了旧的bug,带来了新的bug。形象的比喻就是:
劣势
成本增加,使用TDD开发
成本和收益
值得么?
确实,TDD可以降低后期的维护成本;但是,降低多少呢?和现在的投入相比,收益如何呢?更重要更重要的一个问题:能这个项目有后期维护么?99%的互联网项目,根本就活不到后期维护好吧?
就飞哥个人而言,更愿意取一个折中:
仅为“核心”代码使用TDD,引入单元测试。
什么是核心代码呢?大致来说,复杂的、被大量使用、被反复修改的……,都可以算。但最终还是要靠开发人员根据实际情况具体掌握了。
提示:
体会:软件项目的复杂性。(区别于:算法复杂度)
非常简单的、琐碎的代码通过组合,就能够带来层出不穷的、此起披伏的bug:按下了葫芦浮起了瓢!
多快好省!前端后端,线上线下,名师精讲
更多了解 加:

