复习:
以数组为例,在大多数语言中(C#/Java)中:
注意上面第4条,这是我们理解数组的关键,这也是数组被如此广泛使用的原因:我们不是从数组中第1个元素开始,依次挨着数(找)第2个第3个……直到第n个,而是通过运算直接得到第n个数组元素的地址!所以,取数组中第2000个元素,并不会比取数组中第2个元素慢。

但在JavaScript中,数组的底层实现不是这样的,它实际上采用哈希表和链表的方式,存储数组元素。@想一想@:为什么?
飞哥推测(为什么是推测?/捂脸.jpg:语言本身只定义语法,不管底层实现)是因为JavaScript弱/动态类型的原因。

但不管底层是如何实现,只要一个东东,能让我们从0开始按下标存取数据,它就是数组。(领会:逻辑概念)
数组一般又可分为:
需求:将数组中的数字(比如:9 2 3 5 4 7 6 8 1 0),按从小到大的顺序排列
PS:憋说你一眼就看出来啦……
建议:在学习冒泡排序之前,先@想一想@自己的方案,比如,可不可以:
PS:读别人的代码,比自己写还难
PPT动画演示:
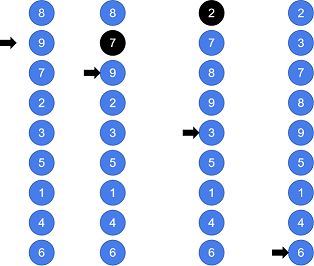
其核心就是:
光说不练假把式!上代码:
//从小到大
for(let i=0; i<arr.length-1; i++){
if(arr[i] > arr[i+1]){
for(let j=i+1; j>0; j--){ //j从大到小了
if(arr[j] < arr[j-1]){
//交换数组元素
let temp = arr[j];
arr[j] = arr[j-1];
arr[j-1] = temp;
}else{
break; //注意:提高性能!
}
}
} //else nothing
}
猜数字的游戏(1-1000),你会怎么猜?
其实,你这种猜测方法,归纳出来就是二分查找法。
以下代码演示:
let arr = [3, 8, 7, 12, 23, 35, 46, 59, 70, 108];
let target = 8; //也可以给一个数组中不存在的值,比如72 //找不到 -1
let left = 0, right = arr.length, i = Math.floor((left+right)/2);
while(target!=arr[i]){ //是这样的吗?
if(target > arr[i]){
//改left还是right?怎么改
}else if(target < arr[i]){
//是不是类似于:left = ?
}else{ //找到了
//找到 index
return i; //?
}
//可以和循环前的i赋值合并么?
i = Math.floor((left + right)/2);
}
月薪18K的算法,^_^
先上PPT演示:

总结:
为什么不能简单的按照上述描述进行coding?
受限于“数组”的特征:定长定位。没有int[-1]啊!数组的操作只有一个:交换(swap)
#悟#:运动是相对的。
所以,衍生出来如下方法:(PPT演示)
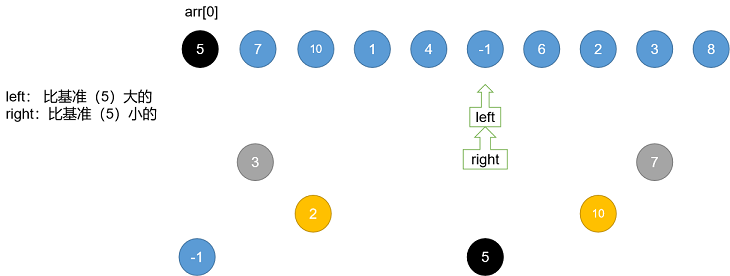
其核心步骤包括:
演示代码:
let arr = [18, 7, 5, 9, 12, 23, 16, 32, 1, 3];
let i = 0, left = 1, right = arr.length-1;
while(left<right){ //循环条件
while(arr[left]<arr[i]){
if(left==right){
break;
}
left++; //一直加到 arr[left]>=arr[i];
}
//停下来,准备交换
while(arr[right]>arr[i]){
if(left==right){
break;
}
right--;
}
if(left == right){ //如果左右指针已经重合
if(arr[left]>arr[i]){
swap(arr, left-1, i);
}else{
swap(arr, left, i);
}
}else{
swap(arr, left, right);
left++;
right--;
}
}
完成一轮排序之后,如何对其左右两部分再进行一次排序呢?而且还要将这个过程一直执行下去呢……
童鞋们,这就是典型的递归啊!
首先,将每一轮的排序抽象成方法:
function quickSort(arr, left, right){ //@想一想@:为什么要left和right参数?
#小技巧#:记录下每一轮排序前的oldLeft和oldRight:
let oldLeft = left, oldRight = right;
一轮排序完成之后,继续调用方法自己:(@想一想@:middle是啥,从哪里来?)
//左边排序 quickSort(arr, oldLeft, middle - 1); //右边排序 quickSort(arr, middle + 1, oldRight);
特别注意,一定要想好递归结束的条件:
if (left >= right)
{
return;
}
@想一想@:冒泡排序和快速排序哪一个更快?为什么呢?
我们使用复杂度来衡量一个(比较各个)算法的效率:
而冒泡排序法,只耗费了多少额外空间?一个元素对应的临时变量而已。
这种算法所需的额外存储空间多少,就是空间复杂度。
按字面意思,是指完成某个算法需要消耗的时间。
但因为耗时受硬件影响,不够客观,我们我们通常以运算(循环)次数衡量。
PS:理解不同语义下的“复杂”:执行 v.s. 设计
同时,算法还受数据影响
用大O表示,指示所需运算(循环)次数和参与运算元素之间的关系,一般包括三个量级:

@想一想@:冒泡和快速排序,遍历和二分查找的复杂度。
为什么是:数据结构和算法,而不是算法和数据结构呢?揭示:
算法依赖于数据结构。
@想一想@:能举一个例子么?
多快好省!前端后端,线上线下,名师精讲
更多了解 加:

