所以初学者很容易把他们当成另一种“表”。
数据库为我们预先准备的、像“表”一样的、有名字有column的系统视图(system view):
| T-SQL | mysql |
|
系统数据库master下面的Views文件夹 |
sys数据库下Views文件夹 |
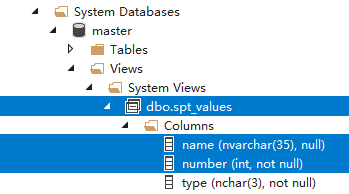 |
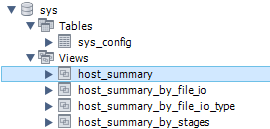 |
我们可以像使用表一样进行查询:(复习:索引视图)
SELECT * FROM sys.indexes;
但实际上,视图也属于表表达式(复习),是根据查询(SELECT)语句计算或整理出来的“虚拟表”。
使用视图,通常是为了屏蔽复杂的表间关系,给用户呈现一个经过整理的、清晰整洁直观的、表结构的数据。换言之,就是为了用户可以像使用表一样的使用视图。
我们也可以定义自己的视图。
比如,将Student表的Enroll拆分成年/月/日三列,其SQL语法如下:
CREATE VIEW V_Student -- V_Student是新创建View的名称 AS SELECT Id, SName, YEAR(Enroll) YearEnroll, -- 新增的计算列 Month(Enroll) MonthEnroll, -- T-SQL要求必须指定列名 Day(Enroll) DayEnroll, -- 列名不能重复 Age, Score, IsFemale FROM Student; -- 还可以添加其他的JOIN/UINION/WHERE/GROUP/HAVING等子句
运行之后,我们就可以看到V_Student已经生成了:
| T-SQL | mysql |
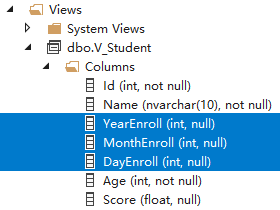 |
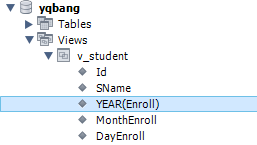 |
注意这个视图是持久化在数据库中的,除非显式删除,否则就不会消失(复习:和“派生表”的区别)
演示:重启数据库,视图仍然存在
和DROP表类似,使用如下SQL语句:
DROP VIEW V_Student;
使用ALTER VIEW:
ALTER VIEW V_Student AS SELECT Id, SName, YEAR(Enroll) YearEnroll, Month(Enroll) MonthEnroll, -- Day(Enroll) DayEnroll, -- 不要DayEnroll列 Age, Score, IsFemale FROM Student WHERE IsFemale = 0 -- 添加一个WHERE条件
但不能像修改表结构那样,使用ADD|DROP|ALTER COLUMN|CONSTRAINT……之类的语法,只能像创建视图一样,重写一遍。
上述这样创建的视图被称之为标准/简单视图,其特点是:
数据库中存储的视图其实就是创建视图的SELECT语句,而不是实际的物理数据。你看到的视图的行和列其实都直接来自于创建视图的“基”表。
所以,在基表上进行数据的增删改,一定会影响到视图的查询结果(演示:略)
反过来,在视图上进行的所有增删改,其结果也会反映到基表上。比如,执行以下SQL语句 :
UPDATE V_Student SET Score = 0 WHERE Id = 1 -- 修改视图V_Student SELECT * FROM Student -- 基表Student数据发生了改变 DELETE V_Student WHERE Id = 1 -- 修改基表Student SELECT * FROM V_Student -- 视图的查询结果发生了改变
注意通过视图更改删除数据,
UPDATE V_Student SET YearEnroll = 2020 -- YearEnroll是通过YEAR(Enroll)获得的T-SQL还没有智能到可以“逆向计算”,因此将基表Student中的Enroll从'2019/2/28'改成从'2020/2/28'!
当用户使用视图的时候,还容易出现这么一种“诡异”的情况:明明插入了一条数据,但就是在数据库里找不到。
修改上面视图,添加一个WHERE子句:
GO ALTER VIEW V_Student AS SELECT Id, SName, Enroll, score FROM Student WHERE Score > 60;
然后插入—条数据,注意Score值:
INSERT V_Student_Schema VALUES(20, 'hp', '2019/10/31', 38);
一切都OK,但在V_Student中查找,就是找不到插入的这条数据。(演示)
@想一想@:为什么呢?
关键就在于插入的这一行数据Score=38,这是小于60的,所以
这有时候就会让不明就里直接使用视图的用户摸不着头脑。
为了避免这种情况,我们可以在创建/修改视图时,在末尾添加:
WITH CHECK OPTION; -- 添加到WHERE子句之后
以确保每一次通过视图插入或更改的数据,一定符合创建视图时WHERE子句的限定。
演示:再次试图插入Score<=60的数据报错。
PS:视图和基表之间“同步”的只是(行)数据,不是(列)结构。所以我们在基表中删除一个在视图中使用的列,再在视图中进行查找,会直接报错:
所以,为了能够一眼看到视图和基表的结构差异,建议尽量不要使用 SELECT * FROM...,而是挨个的写明视图要使用的列,比如 SELECT Id, [Name], Age FROM...
Stored Procedure其实和函数(函数的早期名字也叫做“过程”)类似,是:
可以:
存储过程是“面向数据库”编程的产物,几乎所有的业务逻辑都可以放在存储过程中,数据库主导一起!
但现在的趋势是尽量不使用存储过程(去存储过程),把业务逻辑放在面向对象的后端语言(Java/C#)中。
为什么还要学习?开发过程中有可能:
#常见面试题:存储过程的优缺点?#
优点:
缺点:
演示:查看数据库下文件夹 Programmability - Stored Procedures - System Stored Procedures中系统存储过程:
所有系统存储过程以sp_开头。所以,建议用户自定义的存储过程不要以"sp_"开头,而是使用其他字符标识(比如usp_开头)
演示常用系统存储过程:
sp_helptext:
EXECUTE sp_helptext 'sp_rename'; -- 显示sp_rename的内容
EXEC sp_rename 'Score', 'Exam', 'object'; -- 将Score表命名成Exam
可以看出,存储过程的调用和函数类似,需要的是:
自定义创建存储过程如下所示:
CREATE PROCEDURE GetExcellentStudents -- 创建存储过程GetExcellent SQL ( @score INT = 80, -- 输入参数回score,默认值为80 @count INT OUTPUT -- 输出参数@count ) AS -- UPDATE Student SET Score = @score; -- 存储过程可以进行写操作 SELECT * FROM Student WHERE Score >@score; -- 给输出参数@count赋值 SET @count = (SELECT COUNT(*) FROM Student WHERE Score > @score) ;
注意在T-SQL中:
调用时其他和系统存储过程一样,只是:
EXEC GetExcellentStudents DEFAULT, ...
DECLARE @count INT; EXEC GetExcellentStudents 60, @count OUTPUT; SELECT @count;
演示:查看sys数据库下Stored Procedures
系统存储过程。
调用和T-SQL类似:
CALL `sys`.`table_exists`( 'yqbang', 'student', @otype -- 输出参数,必须加@前缀 ); SELECT @otype;
除了:
创建存储过程最好在mysql中:Stored Procedures右键Create……,然后在弹出代码中填入:
CREATE PROCEDURE `GetExcellentStudents`
(
p_score INT , -- 输入参数回score
OUT p_count INT -- 输出参数@count
)
BEGIN
-- 具体存储过程执行内容
END
点击Apply按钮之后会发现多出一些代码,其中最关键的就是:
DELIMITER $$ DELIMITER ;
这实际上就是告诉mysql:在其间的区域,用$$代替分号(;),以避免mysql碰到分号就直接解释执行了。
------------------------------------
T-SQL和mysql共同演示:
------------------------------------
和创建存储过程一样,可以使用SQL创建函数的(FUNCTION)
演示:系统函数(不同于内置函数)
#常见面试题:#
1、存储过程和函数有什么区别?
基本上,函数能干的事情存储过程都能干。
存储过程没有RETURN的使用,但它可以用OUTPUT设置输出参数,实现函数一样的的效果。
另外,存储过程没有函数只读不写的限制
这就是存储过程的使用比函数更为普遍的原因。
2、何时使用存储过程,何时使用函数?
除了上述的语法的比较,我们建议再加上很重要的一条:按需要选择。
如果你的需求是:得到—些数据以便于数据库内部使用,可以使用函数;否则,使用存储过程。
参考:Function vs. Stored Procedure in SQL Server
SQL也是一种编程语言(Language),所以它一样可以:
|
|
T-SQL | mysql |
变量
|
DECLARE @name VARCHAR(20) = 'feige'; DECLARE @name VARCHAR(20) --,@age INT; SET @name = 'feige'; |
DECLARE Sname VARCHAR(20); DECLARE Age INT; -- SET Sname = 'feige'; |
|
都使用关键字DECLARE(声明)和SET(赋值) |
||
|
变量名都必须以@开头 可以声明的同时赋(默认)值 可以一次声明多个变量 |
变量名都不能以@开头 |
|
分支
|
IF @age>18 BEGIN SELECT 'Adult'; SELECT 'Congratulation!'; END ELSE IF @age > 12 SELECT 'Teenager'; ELSE SELECT 'child'; WHILE @age>0 BEGIN SELECT @age; SET @age = @age-5; END |
IF age>18 THEN SELECT 'Adult'; SELECT 'Congratulation!'; ELSEIF age > 12 THEN SELECT 'Teenager'; ELSE SELECT 'child'; END IF; WHILE age>0 DO SELECT age; SET age = age-5; END WHILE; |
|
多行内容必须用BEGIN...END包裹 |
不能使用BEGIN...END 不要忘了IF、ELSEIF后面的THEN 用ENDIF结尾 |
|
异常 |
BEGIN TRANSACTION
BEGIN TRY
UPDATE Student
SET Score = Score + 50
WHERE Id = 1;
UPDATE Student
SET Score = Score - 50
WHERE Id = 2;
SELECT 'success';
COMMIT TRANSACTION
END TRY
BEGIN CATCH
IF @@TRANCOUNT>0
BEGIN
SELECT 'failed';
ROLLBACK;
END;
-- THROW; 异常还可以再抛出
END CATCH
|
-- 声明:当有SQL异常时退出
DECLARE EXIT HANDLER FOR SQLEXCEPTION
BEGIN
-- 单行可省略BEGIN...END
SELECT 'failed';
ROLLBACK;
END;
start transaction;-- 注意位置
UPDATE Student
SET Score = Score + 50
WHERE Id = 1;
UPDATE Student
SET Score = Score - 50
WHERE Id = 2;
SELECT 'success';
commit;
|
语法和其他编程语言(Java/C#)类似TRY...CATCH(异常捕获):
|
没有TRY...CATCH的语法 而是使用:DECLARE...FOR语句 |
|
说明:以上mysql语句都应/只能在存储过程或函数体中,且变量名前不能加@前缀。
但如果是在存储过程或函数体外,可以直接赋值一个带@前缀的变量,不用声明:
SET @name = 'feige'; -- 存储过程/函数外
无论T-SQL还是mysql,两个@@引导的都是全局变量(如@@IDENTITY),全局变量只能由数据库声明赋值等。
trigger,是可以在进行某些数据库操作(增删改)时自动触发,并执行的一段代码内容,一般被视为一种特殊的存储过程。
案例:现有积分记录表Points
CREATE TABLE Points
(
Id INT NOT NULL PRIMARY KEY,
Amount INT,
Balance INT DEFAULT 0
);
Id和Amount记录了每一次的积分变更。
我们希望:每一次新增一条积分记录,就可以自动的统计出当前总的积分,存放在Balance中——这就可以用触发器实现。
对比演示:有/没有触发器时的情形
INSERT Points(Id, Amount) VALUES(1, 5); INSERT Points(Id, Amount) VALUES(2, 3);以下结合文档演示说明:
| T-SQL |
mysql |
CREATE TRIGGER TRG_Caculate
ON Points
FOR INSERT
AS
BEGIN
UPDATE Points
SET Balance = (SELECT SUM(Amount) FROM Points)
-- inserted代表刚插入的数据
WHERE Id = (SELECT Id FROM inserted);
END
|
CREATE TRIGGER trg_caculate
BEFORE INSERT -- 在行插入以前
ON points FOR EACH ROW
-- 对新插入行(NEW)中的数据进行替换
SET NEW.Balance =
NEW.Amount +
(SELECT SUM(Amount) FROM Points);
|
|
简介 示例/详细介绍 API文档 |
|
|
大写:关键字 斜体小写:需由开发人员填写的内容 []:可以使用,也可以不使用 {}:必须使用 |:并列可选项 |
|
|
[ ,...n ] <>:占位 ::=:对占位的说明 |
|
创建触发器TR_KeywordUsed,能在关键字变动(求助发布/修改/删除)时重新统计关键字被使用次数Used
多快好省!前端后端,线上线下,名师精讲
更多了解 加:

