复习:数据结构和算法 - 树
@想一想@:当运行如下SQL语句的时候
SELECT * FROM Student WHERE Id = 986;
时,数据库如何才能快速的找到目标行?
如果没有建立索引,数据是散乱的、无序的堆放在一起的,只有进行全表扫描:
从表中逐行的取出数据,对比其Id是否为986……
@想一想@:这样的算法复杂度是多少?O(n)
为了提高查询效率,数据库引入索引(Index)。
索引对应的数据结构就是树——为了更进一步的降低查询树的深度(提高查询效率),一般数据库使用的是“多叉平衡查询树”(BTree/红黑)。
@想一想@:索引的算法复杂度是多少?O(lg(n))
比如我们说:给Student表的Id列“加”一个索引,其实就是以Id列的值构建一个树。这样我们以后根据Id查找的时候就会更快捷
索引分为以下几种:
聚集(clustered)索引的叶子节点直接存放的就是行数据,比如Student的Id姓名年龄等。
根枝节点里存放的,我们称其为索引数据,比如Id为1-2的Student存放在P1中,Id为3-4的Student存放在P2中……
其中1/2/3/4……又被称之为索引键值,其实就是建立索引的列值。
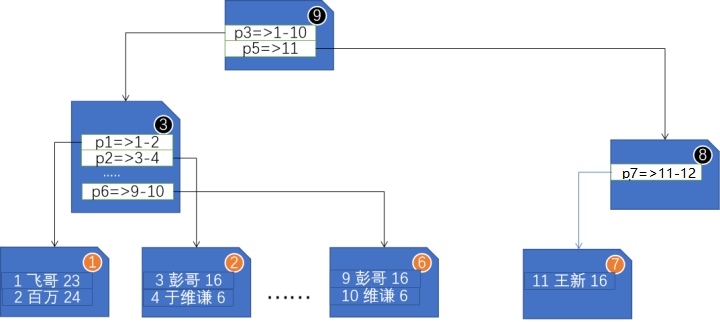
我们可以认为:聚集索引就是直接“包含”行数据的,所以一个聚集索引就可以代表一个表。
表和聚集索引是“一体两面”的:
同理,每张表只能有一个聚集索引。
和聚集索引不同,非聚集(non-clustered)索引的叶子节点中存放的不是实际的行数据,而是指向行数据的“指针”。
指针可以被认为“行定位器”,具体来说,这里的指针分为两种:

所以,实际上当我们使用非聚集索引进行查找时,并不能直接的获取目标行数据。
我们还得再根据其叶子节点中存储的“指针”,再进行一次查找,最终才能获得行数据:这就是“聚集索引比非聚集索引快”的原因。
和聚集索引不同,一张表可以创建多个非聚集索引。
如果列上的值是唯一的,我们就可以在这个列上建立唯一(UNIQUE)索引;
否则,我们就只能在其上建立非唯一索引。
但在底层实现上,通常只有唯一索引。比如SQL Server就是给所有的索引键值中添加一个后缀uniquifier:
数据库在我们建立以下约束的时候,就会自动建立索引:
设立主键(PRIMARY KEY)约束时,(如果表上还没有建立聚集索引)会自动创建一个聚集唯一索引。
设立唯一(UNIQUE)约束:会自动创建一个唯一非聚集索引。
因为唯一约束需要在插入数据时进行“唯一”检查,检查的方式就是在该列已有值中查找插入值:
出于效率考虑,就不可能使用全表扫描,而只能通过唯一索引来快速查找。
所以,唯一约束本质上是依赖唯一索引的;而且,唯一约束和唯一索引具有相同的作用(确保列值唯一),不宜在已有唯一约束列上再建立一个唯一索引。
| SQL Server | mysql |
|
还是区分开了约束和索引:
|
可以认为:约束就是索引
|
除了通过约束自动建立索引,还可以主动:
为了便于演示(此处演示用mysql workbench),我们新建一个表Teacher:
CREATE TABLE Teacher(Id INT, TName VARCHAR(25), Age INT, Gender BIT);
建立索引建立索引时需要:
示例如下,在Teacher表Id列上建一个:
CREATE INDEX IX_Teacher_Age ON Teacher(Age);
CREATE UNIQUE INDEX IX_Teacher_Id ON Teacher(Id);
多个索引还可以建立在同一个列上。比如Id列上还可以(通过主键约束)建立聚集索引:
ALTER TABLE teacher ADD constraint PK_Teacher_Id primary key(id);索引还可以被建立在多个列上,比如:
CREATE INDEX IX_Teacher_Age_Gender ON Teacher(Age, Gender)IX_Teacher_Age_Gender是一个而不是两个索引,它建立在Age和Gender两个列上。这种索引的键值是Age和Gender的组合,和IX_Age或IX_Gender并不重复。(多列的索引在WHERE子句同时包含多列时有用)
当一个数据库年代久远、被多人操作时,我们很容易在一个列上建立冗余的索引,既占用空间又拖累性能的。为了避免这种状况:
删除索引时需要同时指定表名和索引名称,如下所示:
DROP INDEX IX_Teacher_Age ON Teacher;
删除索引不会删除表数据,如果索引是:
#体会#:索引和表是独立的、相互分离的
可以指定索引为CLUSTERED(仅当表中没有设立主键约束时):
CREATE CLUSTERED INDEX IX_Teacher_Name ON Teacher(TName);
CREATE UNIQUE CLUSTERED INDEX IX_Teacher_Name ON Teacher(TName);
注意和UNIQUE的先后顺序。
使用系统视图sys.indexes演示:
-- [type]:1 聚集; >1 非聚集
SELECT [Name], [type], is_unique, is_primary_key, is_unique_constraint
FROM sys.indexes
WHERE object_id = OBJECT_ID('Student')
所以如果(SQL Server)面试官问你:主键就是唯一聚集索引吗?你正确的回答是:不一定……
通过执行计划(execution plan)我们可以查看数据库有没有使用到索引。
首先,我们要明白:SQL语句是指令性的,结果导向的!换言之,SELECT语句只是给出了对查询结果的要求,而没有给出具体的执行步骤。(复习)
因为一条SQL语句(尤其是当它比较复杂的时候)的目标,可能有多种途径实现,所以数据库在得到SQL语句之后,会
所以不要有这种错觉:
SELECT语句的不同书写方式可以决定数据库的执行方式。
注意:不是这样的!至少不完全是这样的。
#体会#:对数据库进行性能优化,查看并理解执行计划至关重要。
演示:VS中打开执行计划(GUI可视化,推荐)
我们通过查看执行计划,来进一步验证SQL Server是否使用索引、如何使用索引。
Scan用于查找全部数据,通常可以由以下SQL语句引发:
-- 没有WHERE子句,查找的就是全表 SELECT * FROM Student -- 表上没有索引 SELECT * FROM Student WHERE SName = 'atai'在执行计划图中用扫描(Scan)标识:

通常来说,如果表上
不进行全表扫描,(因为使用索引)可以只比对部分索引键值就获取到所需数据。通常可以由以下SQL语句引发:
-- Student表在Id上建立了聚集索引,注意SELECT后是* SELECT * FROM Student WHERE Id = 3 -- Student表在Age上建立了非聚集索引,注意SELECT后仅有Age(实际上是不是没有意义?) SELECT Age FROM Student WHERE Age = 23在执行计划图中用查找(Seek)标识:

-- Student表在Age上建立了非聚集索引,注意SELECT后改成了* (不再是Age) SELECT * FROM Student WHERE Age = 23
当我们利用非聚集索引进行查找,且要求返回除索引键值以外的行数据时,因为非聚集索引的叶子节点上没有存放实际的行数据,所以还需要再进行一次查询(复习)。
在执行计划图中就会表现为这种形式:
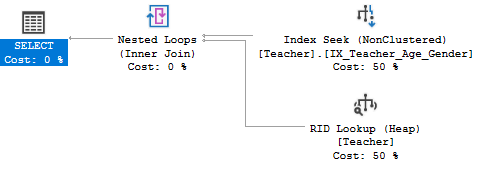
除了之前我们讲过的Index Seek,还出现了RID Lookup(Heap),这就是基于非聚集索引查找结果的再次查询。
即根据表上是否已建立聚集索引,Lookup又可以分为:

在explain后面直接跟SQL语句,执行就会得到如下结果:

其中possible_keys和key就涉及到是否使用,以及使用了何种索引。
更多可见mysql官方文档。
@想一想@:是不是只要我们在表上建立了索引,并利用该列进行SELECT查询,数据库就一定会使用该索引?
我们在IsFemale上建立索引,并执行如下SQL语句:
SELECT * FROM Student WHERE IsFemale = 0
我们发现:执行计划直接使用了Table Scan,根本没有理会在Gender上建立的索引IX_Student_IsFemale!

为什么呢?
因为IsFemale是BIT类型的,而BIT类型的索引——索引值会大量重复——是非常低效的。
所以,SQL Server认为使用索引比不使用索引更慢,于是即使有索引,SQL Server也不会在执行计划中使用索引!
—— 这就被称之为索引失效。
除了上述原因,常见的还有:
SELECT * FROM Student WHERE Id*3 = 10
SELECT * FROM Student WHERE SName LIKE 'a%'; -- 可以用到索引 WHERE SName LIKE '%tai%'; -- 无法用到索引
SELECT * FROM Student WHERE SName NOT LIKE 'a%';
SELECT * FROM Student WHERE Id = 1 -- OR语句导致前面的Id查询使用索引没有意义 OR SName LIKE 'a%';
天下没有免费的午餐,凡事皆有代价!这是我们在做性能优化的时候尤其要牢记的一点(尤其是“性能控”的同学)。具体来说,索引会:
创建索引
CREATE FULLTEXT INDEX ft_index ON ttx_dev.companylicense (FullName) WITH PARSER ngram
ngram是mysql内置的中文分词器
在mysql.ini中可以指定分词长度:ngram_token_size
忽略警告:FTS_DOC_ID是mysql为全文检索自动创建的一个列
使用索引
SELECT * FROM ttx_dev.companylicense
WHERE MATCH (FullName) AGAINST ('首顾')
;
如果要在Message上建索引,你会如何规划,为什么?
如果要在Message上建索引,你会如何规划,为什么?
多快好省!前端后端,线上线下,名师精讲
更多了解 加:

