我们还可以在列名前面添加关键字:DISTINCT:以返回“唯一”行,即相同的行会被合并成一行显示。
或者你可以理解为:相同的行只显示一行。
比较有无DISTINCT的查询结果:
SELECT Age FROM Student; SELECT DISTINCT Age FROM Student;
如果SELECT的是多列,那就需要所有列的值都完全相同,才会被认为是“相同的行”,才会被“合并”。比如:
SELECT Age,Score FROM Student; SELECT DISTINCT Age,Score FROM Student;

上图中(左)第2行和第5行,Age和Score都完全相同,所以会被合并成1行;第4行虽然Age=19,但Score为NULL,和第2行第5行的Score=89不同,所以不能被合并。
注意:NULL值和NULL值相比,会被认为是相同的。
可以将数据按某种特定顺序,有序的显示出来。
ORDER BY 后面直接跟列名,比如:
SELECT * FROM Student ORDER BY Score;就是按Score列的值进行排序,默认是按升序(从小到大,ASC)排列。如果要降序(从大到小)排列,需要再添加一个关键字:DESC
SELECT * FROM Student ORDER BY Score DESC; -- 按成绩从大到小排列
除了数值,其他各种数据类型,比如日期、文本,都可以进行排序。(但是,TEXT和image等类型除外)
ORDER后可以跟多个列,比如:
SELECT Id, Age, Score FROM Student ORDER BY Age ASC, Score DESC这就是要求:
所以,其结果就是:
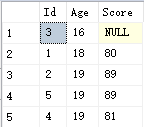
注意:使用ORDER进行排序时,NULL被认为是“无限小”
SELECT还可以进行分组统计,比如,我要查询Student表中不同年龄(Age)的学生,各有多少人,怎么办?这就需要使用:
SELECT Age, COUNT(*) -- COUNT()是统计个数的“聚合”函数 FROM Student GROUP BY Age -- 按Age分组
运行上述SQL的结果就是:
也就是说:
SELECT Age,Score, COUNT(Score) FROM Student GROUP BY Age, Score
意思是按Age和Score进行分组,Age和Score都相同的为一组。
先打预防针,^_^,同学们使用GROUP BY的时候容易犯的两个错误:
SELECT Age, -- Age是可以的 Score, -- Score不能在这里,因为GROUP BY后面没有跟Score COUNT(*) -- 但在聚合函数中可以使用任何列 FROM Student GROUP BY Age
注意:COUNT()被称之为:
GROUP BY使用的聚合函数,除了COUNT(),还有:
以上聚合函数,圆括号中都要指明列名,比如:
SELECT Age, SUM(Score) FROM Student GROUP BY Age;
#常见面试题#:COUNT(*) / COUNT(Score) / COUNT(1)的区别?
前提知识点:NULL值在聚合函数中自动忽略,不被纳入统计(演示)
聚合函数中的NULL值会被略过(不纳入计算)。
另:聚合函数还可以独立(没有GROUP BY)使用
SELECT MAX(Score) FROM Student
我们还可以使用HAVING子句对分组后的结果进行过滤:
SELECT Age, AVG(Score) FROM Student GROUP BY Age HAVING AVG(Score) > 85
演示:比较没有HAVING过滤,和有HAVING的区别。
可以同时使用HAVING和WHERE,但要注意HAVING和WHERE的区别:
综合上面全部知识点,生成以下SQL语句:
SELECT DISTINCT Age, MAX(Score) FROM Student WHERE Enroll < '2022-12-1' GROUP BY Age HAVING MAX(Score)>60 ORDER BY Age DESC;
@想一想@:数据库执行的步骤是怎样的?
查看执行计划,可以看出单表查询的顺序是:
#试一试#:
SELECT DISTINCT Age, MAX(Score) AS MaxScore FROM Student GROUP BY Age HAVING MaxScore>60;报错:Invalid column name 'MaxScore'.
演示:文章分页
@想一想@:分页的本质是什么?
以每页10条数据为例,第3页就是“跳过”20页之后再取10页。
注意:不能直接用Id,BETWEEN 20 AND 30,因为Id不一定是连续的!
曾经很复杂,现在很简单。在:
SELECT * FROM Student ORDER BY Score
之后添加:
|
|
T-SQL | mysql |
|
跳过1行取2行: |
OFFSET 1 ROWS FETCH NEXT 2 ROWS ONLY; |
limit 1,2 |
| 只取前2行(简写) |
SELECT TOP 2 * FROM Student |
limit 2 |
| 跳过第1行之后所有行 |
OFFSET 1 ROWS; |
无 |
准备表和数据:
CREATE TABLE Scores ( SName VARCHAR(10), Major VARCHAR(10), Score FLOAT );
INSERT Scores VALUES('atai','C#', 98);
INSERT Scores VALUES('atai','SQL', 89);
INSERT Scores VALUES('atai','JavaScript', 76);
INSERT Scores VALUES('xj','C#', 87);
INSERT Scores VALUES('xj','SQL', 95);
INSERT Scores VALUES('xj','JavaScript', 58);
进行查询,添加一列,按以下规则显示:
这就要使用到:CASE..WHEN...THEN...ELSE…:
SELECT SName, Major, Score, CASE -- CASE的启动 WHEN Score>=80 THEN 'Excellent' WHEN Score>=60 THEN 'Pass'-- 注意排序! ELSE 'Failed '-- 之前的条件均不能满足 END AS Grade -- CASE的结束 FROM Scores;
其结果为:
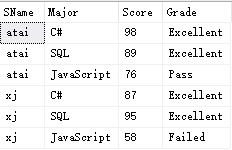
这段SQL语句关键的就是︰
使用该语法时还要注意:正确控制逻辑判断顺序,如果满足了第一个WHEN的条件,就不会继续下—条的比较。所以……
CASE语句的运算结果类似于一个“列值”,所以并不仅限于SELECT子句,而是几乎可以用于任何操作,比如UPDATE。
我们可以在Student上先添加一个列:
ALTER TABLE Scores ADD Grade VARCHAR(25);然后使用UPDATE语句进行填充:
UPDATE Scores
SET Grade = CASE
WHEN Score>=80 THEN 'Excellent'
WHEN Score>=68 THEN 'Pass'
ELSE 'Failed '
END;
如果只是进行简单的“等于”比较,就可以使用简写形式。比如,将IsFemale中的1转换成女,0转换成男,就可以:
CASE IsFemale WHEN 1 THEN '女’ELSE '男' END
最后,我们来学习一个经典的
#常见笔试题目#
需求就是将下图左表转换成右表格式。
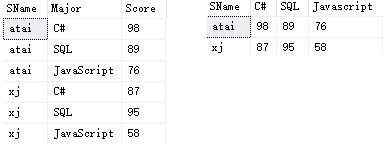
首先,要在SName后面添加三列:
SELECT SName, CASE Major WHEN 'C#' THEN Score ELSE 0 END AS 'C#', CASE Major WHEN 'SQL' THEN Score ELSE 0 END AS 'SQL', CASE Major WHEN 'Javascript' THEN Score ELSE 0 END AS 'Javascript' FROM Scores;
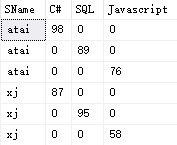
SELECT SName, MAX(CASE Major WHEN 'C#' THEN Score ELSE 0 END) AS 'C#', MAX(CASE Major WHEN 'SQL' THEN Score ELSE 0 END) AS 'SQL', MAX(CASE Major WHEN 'Javascript' THEN Score ELSE 0 END) AS 'Javascript' FROM Scores GROUP BY SName;
多快好省!前端后端,线上线下,名师精讲
更多了解 加:

