广泛应用,比如7层网络协议
没有什么是分层不能解决的,如果分层还不能解决,就再分一层。
代码太多,需要组织:分层架构属于“纵向”组织。(组织代码/人手)
职责分离(单一职责),方便项目组织维护,甚至是重用。
把企业由上到下应用分成:
所谓分层,就是将代码放置到不同的“层”中:

其关键点为:
接下来以“注册”为例,我们梳理一下它包含的功能,各自应该放到哪一层:
应完成数据库相关操作:
一切OK,但BLL层呢?
有一种说法,BLL层“无事可做”是因为业务逻辑太简单,是这样吗?
我们扩展一下注册的功能,比如:注册成功之后,新注册用户和邀请人的帮帮币+10。你怎么设计业务逻辑?
你是不是又想到了UPDATE语句?在数据库里面更新当前用户和邀请人的帮帮币数量?
如果你一直是这种思路,那整个项目,除了UI,就是DAL,所有的业务逻辑本质上就是数据库的增删改查……我将其称之为:面向数据库编程。
尤其是大量的使用存储过程,将更多的逻辑被封装到存储过程之后,BLL就完全没有存在的价值了……
PS:你走上工作岗位之后或许就会发现,大多数项目就是面向数据库编程,真香!
Domain Design Driven,简称DDD,是解决薄BLL层的一剂良药。简单理解:
即使学了关系型数据库,我们仍然像学Java/C#时一样,通过Repository保存/读取/删除各种对象,相信只要对象进了仓库,就可以持久化。
唯有这样,我们才能保持我们“面向对象”而不是“面向数据库”的思考。
至于repository怎么持久化这些对象,不是有ORM么?
#体会#:使用ORM工具,一不小心总是会产生额外的SELECT语句,为什么?因为ORM本来就是按repository模式设计和开发的,它的基本思路就是:
对象不取出来,直接在数据库UPDATE,是“犯规”的。
#体会:EF中DbContext的注释说明
DbContext is a combination of the Unit Of Work and Repository pattern
带有Id、需要被持久化(放到数据库)的类,构成了BLL的主体。(此外还包括没有Id的ValueType/Component、Helper等)
领域驱动,就可以简单理解成entity驱动。即:我们设计/开发一个功能时,首先想到的是:
仍然以注册功能为例:
至于如何把用户和帮帮币数据保存到数据库,那是对象持久化的问题,是repository做的事情,不用考虑……
DTO(Data Transfer Object):用于数据传递的对象.
Entity肯定是DTO(将数据从BLL传到UI),但除此以外,它还能有其他作用么?
我们选择主流的“充血”模式。
@想一想@:增删改查,和数据库交互……repository不是应该放在DAL层?
很多同学会混淆Repoistory和DAL,因为他们的作用好像都一样?或者认为repository应归入DAL……
我们来看一下,如果Repository是/属于DAL
注意:DAL返回的不能是BLL的对象。@想一想@:那返回什么?只能是数据库结果集(JDBC:ResultSet / ADO.NET:DataReader)。
所以,Repository应该属于BLL。
ORM都超额完成了DAL的功能,^_^,更接近于Repository。
PS:.NET中两个project之间不能相互引用,要想entity要不要引用repository,就只能把entity和repository放在同一个项目中。
让Entity能引用Repository,这样做的好处是方便,比如一个user.Register()可以直接完成所有功能:
class User
{
//包含对UserRepository的引用
private UserRepository userRepository;
public int HelpCredit; //为了便于Java/C#通用,使用字段
public void Register()
{
HelpCredit += 10;
//直接完成User的持久化
userRepository.Save(this);
}
}
问题就是有点乱,上层调用的时候容易犯迷糊,Register()方法究竟有没有完成持久化?因为你很难保证entity的每一个方法都自动持久化的,一个功能的实现,可能需要调用多个方法,每个方法都持久化吗?不然,谁来持久化呢?
所以我们还是采用Entity被Repository引用的方案,这样上层调用的时候就知道,所有的enitity方法都不涉及持久化——持久化的事情自己做,而且可以一次性完成。
此外还有一些额外的好处:
但是,这样Entity就不能再引用Repository,也可能给我们的开发带来不便。主要就是一个对象只能通过引用获得关联对象,当关联的是集合的时候,会造成性能压力(ORM会取出所有数据填充集合)
#总结#:BLL层又被我们分成了两大类:
在UI和BLL之间引入,但这一层不是必须的,但还是有必要的,尤其是UI层是MVC的时候(Restful接口或WebApi本身也就是一种服务)
Service层主要的干活:
class UserService
{
//包含对UserRepository的引用
private UserRepository userRepository;
//UI调用该方法,传入用户名和密码
//public void Register(string name, string password)
//通常使用Model做数据容器
public void Register(RegisterModel model)
{
//伪代码,entity和Model间映射,类似于:
//User user = new User { Name = model.name, Password = model.password };
User user = Mapper.MapFrom(model);
user.Register();
userRepository.Save(user);
}
}
有一些项目之间把BLL的entity当做MVC的Model用,这是有一些问题的(尤其是在MVC中):
因为Model是基于View组织的,而entity是基于业务逻辑组织的,两者之间并不能完全相符。
如果用entity直接做Model的话,常见的问题:
我们采用PerViewPerModel(一个页面一个Model)的模式,所以需要在Service层在entity和Model间进行一个映射(转换)。
为了演示依赖注入的效果和作用,我们为所有Service抽象了接口,并提供两种实现:
class MockUserService : IUserService
{
public int Register(RegisterModel model)
{
if (model.name == "fg")
{
//用户名重复
}
return new Random().Next(100);
}
}
这样做的作用是:假定UI层是一个开发团队,他们就可以不等待ProdService的实现,而利用MockService继续开发。
PS:这和前后端分离时前端mock是一样的道理
其他的好处还有:便于单元测试(避开数据库)制作数据
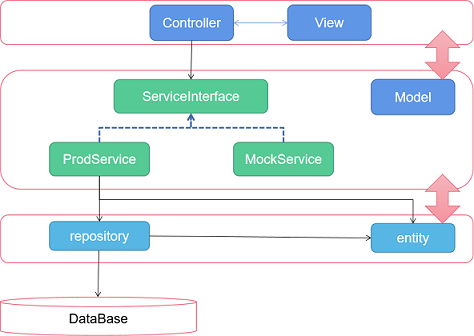
一图胜前言!接下来,讲一讲我们架构中要涉及的两个技术:
Inverse Of Control,控制反转,和依赖注入(Dependency Injection),几乎是同一个意思。
多态:父类变量可以装子类对象。
class RegisterController
{
private IUserService userService;
public Action Input()
{
userService = new ProdService(); //或者
//userService = new MockService();
userService.GetByName("fg");
}
}
如上代码,userService究竟“装”哪一种对象,这个控制权由RegisterController本身决定,这就是控制没有反转,正常的代码。
问题:如果我想要从ProdService切换到MockService,就要去改源代码,到处改……能不能不修改Controller的代码,方便的实现切换呢?
不再是直接new出一个对象,而是从一个容器(container)中获取:
public Action Input()
{
userService = IoCContainer.GetUserService();
class IoCContainer
{
internal static IUserService GetUserService()
{
if (true) //每次切换只需简单更改这里
{
return new ProdService();
}
else
{
return new MockService();
}
}
}
在实际开发中,这个容器不要我们自己写,只需要引入一些框架/类库就OK了。(Java中最流行的是Spring,C#是Autofac或ASP.NET Core自带的Service)
使用的方式更进一步:
public RegisterController(IUserService userService)
{
this.userService = userService;
}
public IUserService UserService{get;set;}
public IUserService getUserService() {
return userService;
}
public void setUserService(IUserService userService) {
this.userService = userService;
}
所以大佬Martin Fowler说:
我想我们需要给这个模式起一个更能说明其特点的名字——“控制反转”这个名字太泛了,常常让人有些迷惑。与多位IoC 爱好者讨论之后,我们决定将这个模式叫做“依赖注入”(Dependency Injection)
其实是一体两面:
既然有了容器,我们就可以对要提供的对象进行更细微的控制,比如scope,(Web开发常用的)可以是:
所以容器做的事其实蛮多了,除了负责对象的生成,还要负责对象的销毁,即对象的整个生命周期。
Aspect Oriented Programming,面向切面编程。(百度百科,你可能会疯掉,^_^)
举个栗子:一起帮里面很多页面都需要登录之后才能访问,所以需要检查用户的登录状态,你怎么办?在每一个页面访问之前都写一段代码/调用一个方法进行检查吗?
@想一想@:还有哪些类似的场景?请求前开启事务,结束后提交事务;日志;计数……
我们把程序中这些零碎但又反复使用的模块视为一个一个的切面,以某种自动化的方式,把切面织入到核心逻辑中:这就是面向切面编程。
再大白话一点:能够不改变程序的核心逻辑代码,但在它运行中的某些时间节点,插入一些额外的代码。
@想一想@:底层实现的工具是什么?反射和代理模式
让每一次Http请求(或独立Action)都使用而且只使用同一个DbConnection/DbContext(EF)/session(Hibernate)!
—— 这就是 Context Per Request 模式。
呈现一个完整的页面,可能会有很多次的数据库操作。以“内容列表页”为例,想一想:
每一次查找,都要使用一次数据库链接,消耗性能。能不能每一个Request请求,都只使用一个数据库链接?在接受到HTTP请求时打开连接,在HTTP请求结束时关闭连接?
减少了DbContext的生成:以前一次Http请求,可能需要new好几个DbContext的,现在一次就OK了。
当然,这样每一个DbConext占用的时间会更长,好在Web项目中每一次Http请求消耗的时间都不会太长,所以通常这都不是一个问题。
几乎所有的Http请求,天然要求“事务”属性。比如用户在文章发布页面点击发布按钮,当然是希望和文章发布相关的所有业务逻辑(比如扣帮帮币加帮帮点生成消息等等)都实现,不可能文章发布失败但帮帮币给扣掉了啥的…… Context Per Request 就能够:
SELECT *
BEGIN TRAN SELECT * COMMIT是一样的么?
@想一想@:如果没有这么一个事先规划好的、已经被填充合适数据的数据库
混乱的数据库,会:
#体会#一个可控的开发/测试用数据库至关重要!
反正都要“做”数据,干嘛不把数据做得更规范更漂亮一些呢?
有的同学会觉得,做数据嘛,那就写SQL脚本……:这就是“面向数据库”!
更好的办法还是要“面向对象”,借用BLL层的entity和repository:
@想一想@:可不可以模拟UI层调用SRV呢?这取决于SRV和UI层的耦合度有多高。生成数据库的项目DbFactory通常都是控制台项目,如果SRV层中
理论上,模拟UI层调用SRV,是一个可选项。但是:
为了有效的构建/管理这些数据,我们需要构思一系列的、用户使用系统的场景,并做好书面记录。我将其称之为剧本。
内容大概类似:
第一天
第二天
以后无论是开发还是测试人员,都可以通过查看剧本,迅速而且直观的知道当前(开发/测试)系统中的数据构成。
早些年,我倾向于认为架构是一种科学,它有一些原则或者规律,我们可以通过理解进行学习;
现在,我倾向于认为架构是一种艺术,架构的好坏要靠我们去感觉,学习的过程更多的是一种模仿;
架构其实是在做一种取舍:
所以,没有银弹,只有“因地制宜”。
分层的问题:
比如项目中使用了两种语言:一些模块用Java开发,一些模块用C#开发;现在我们想在这些模块中实现互相调用,即Java模块调用C#模块,可不可行?
在内存间通信是不可能的啦,但有一种办法:使用网络通信。比如Java模块暴露一个url,只要我们访问这个url,Java模块就能予以响应:这样的Java模块是不是就像服务器一样?它对外提供的,就是一种服务。
最早这种服务的使用只是为了解决不能/难以互相访问的模块之间的通信问题,但后来有人觉得好像所有模块都都这样部署也不错……?于是,SOA(Service-Oriented Architecture),面向服务架构,就被提出来了。
微服务就是微型服务,即:把大量的功能模块都主动的做成一个一个微型的服务。
好处:高度自治,野蛮生长。
想象一个项目小组,负责某个模块某个功能
但这样真的好吗?架构的本质就是纪律规范和约束,否则我干嘛要架构呢,大家一起嗨随便嗨不就OK了?
另外,微服务带来的另一个问题就是大量额外的桩和mock模块。比如我开发一个模块(UI都没有),这个模块怎么被触发启动(需要桩或者测试用例)?我还要调用其他的模块,但其他模块完全可能还未实现或者有问题,怎么办(需要mock)?对其他架构而已,单元测试是一种增益(可有可无),对微服务而言,单元测试是一种标配!
PS:微服务的问题其实类似于前后端分离,但更为严重……以我十年老码农的经验来看,还是可以让子弹再飞一会儿。
限制SOA及微服务的一个重要因素就是部署。
以前你的模块写好了,我代码(通过git/svn)拉下来就能跑,现在要用的模块,首先得部署起来!而部署,其实是很麻烦的,总是能在不经意间遇到各种稀奇古怪的问题……
所以docker应运而生:
Docker是一个虚拟环境容器,可以将你的开发环境、代码、配置文件等一并打包到这个容器中,并发布和应用到任意平台中。
docker就是一个类似于虚拟机、但更轻量级的软件,它可以把一台电脑的开发/部署环境很轻松的拷贝到另一台电脑,解决的问题就是:“在我的电脑上就能跑呀!”有了docker,我们都在docker环境里面跑。
PS:Java方向的同学学Linux的时候,可以直接用docker。
多快好省!前端后端,线上线下,名师精讲
更多了解 加:

