演示:消息列表页面各种消息(作为邀请人被注册,博客被评论,……)
这些消息是:
比如:
对应的底层数据就是:

动态生成节约存储空间,便于控制样式;但是(如果消息种类繁多)每次生成消息都需要大量的扫描/运算,复杂度高,性能消耗大,而且不好解决已读/未读/删除(不能真删)的问题……
所以“一起帮”采用了静态保存的方式,会有一个专门的
一般可保存以下内容:
在“事件触发”(比如:使用邀请人进行注册)时生成……
Message message = new Message
{
Receiver = newPost.Blog.Author,
Content = $"你的博客(id={newPost..Id})被用户(id={newPost.Author.Id})评论……"
};
在哪里生成这个Message?
按DDD充血模式的原则,应该是在entity的方法(比如:Comment.Publish()/User.Register())中。
但新生成的message怎么持久化呢?按我们的架构要求,entity不能引用repository,所以Message对象只能作为关联对象,依赖于“主entity”持久化而持久化:
Receiver.Messages.Add(this);
Bingo,完美!只是要注意:不要在Receiver.Messages的时候,数据库中加载全部的Messages,这是没有必要的(Hibernate能Inverse()绕开,但EF目前还不行)!
所以有些架构会在Service层中new出Message对象,调用repository持久化 public void Comment(int id, Post newPost)
{ //先存Post
newPost.Author = currentUser;
newPost.Blog = _blogRepository.Get(id).SingleOrDefault();
newPost.Publish();
_postRepository.Save(newPost);
//再存Message
_postRepository.Save(message);
//以后还存其他entity
//......
}
这实际上就是把Entity应该做的事情,挪到了Service层,最后会形成了一个臃肿的Service层和一个萎缩的(贫血的)Entity层,还不如Entity和Repository混用呢!
PS:充血的entity应尽可能的“厚”,Service尽快能的“薄”
可以有两种方式:
方式2的做法和Message类似,但有两个不同:
用户现有的积分,如果每次都SUM所有记录汇总的话,计算量还是太大了。
所以可以借鉴银行存折记录格式:(演示)
| 日期 | 增减 | 金额 | 余额 | 备注 |
| 2022年10月17日 | + | 10 | 10 | 注册奖励 |
| 2022年10月18日 | + | 5 | 15 | 签到 |
| 2022年10月19日 | + | 20 | 35 | 发布评论 |
| 2022年10月19日 | - | 30 | 5 | 垃圾广告 |
每次变化都记录一个“当前结余(balance)”数量,
public class Credit
{
public int Balance { get; set; }
这样通过最近一次记录就能马上拿到用户的现有总积分。
但是,这最近一次记录,究竟是:
public class User : BaseEntity
{
public Credit Latest { get; set; }
仍然是两难,¯\_(ツ)_/¯
很多时候,我们拿到User就要使用它的积分。如果每次都要到数据库中查询的话,很不方便的(尤其是在entity中)。
同时为了些许性能提升,我们可以在User中记录其最后一次Credit变更记录:
按上述方式记录积分,实际上就产生了数据冗余。
要考虑到实际项目运行中,有可能出现“误算”的情形
因为按我们的架构要求,Entity不能使用Repository:
Email的发送应该是哪一个层的职责?
实际开发中,Email中的正文内容更加复杂,比如通常会添加一个url连接,比如:
Body = $"点击<a href='http://{host}/Email/Validate?uid={id}&code={code}'>完成注册</a>" ,
看到有html和url,你可能觉得应该是UI层的事;
但是,uid(用户Id)和code(验证码)不都应该考虑:
我们在很多时候(比如重置密码),都需要用户的Email。但在使用之前,需要保证用户输入的Email是:
惯常的办法就是对其进行验证/激活。复习:Email发送
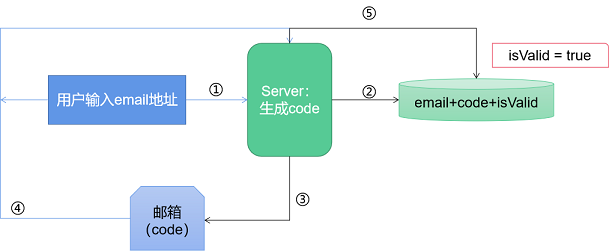
如图所示:
整个流程的关键就在于:用户只能通过他留下的email获取激活code。
限制文件上传大小:不能几十个G的文件啪啪啪的网上传!
方案:
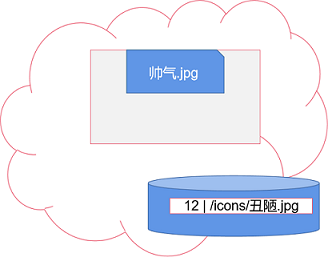
当需要上传的文件/图片很多的时候,一般我们要考虑以下几个因素:
1、重名和覆盖
如果使用客户端上传的文件名,就有可能:后上传的同名文件覆盖/不能覆盖之前保存的同名文件。
我们要考虑用户的意图:
如果要覆盖,我们也有两种方式:
所以会衍生出一个常见的套路:由服务器端重新生成文件名,比如:
当然,在能由路径确保操作的一定是当前用户自己的文件时,我们有可以使用用户自己原有的文件名,实现方式1的同名文件真正覆盖。这就需要规划好文件路径,比如,路径中包含:
2、检索性能
规划好目录树,合理配置文件夹和文件,能够大幅提高文件的检索效率。
都会导致检索文件困难,耗时过多。
飞哥推荐按年/月/日(月日可选)组织,比如:
这样实现起来很简单,而且分布较为均匀。文件的名称可能是:~/images/2020/2/4/5293132738.jpg
静态的文件输出(如:图片呈现、文件下载)是HTML的内容。
但有时候我们会在后台动态的生成一些文件,比如统计报表excel文件、辨别机器人的captcha图片等,这时候要理解:
注意:通常来说,触发消息生成的用户,不是消息的接收人。比如:张三 使用 李四 作为邀请人进行注册,张三的行为触发了消息的生成,但
有两种方式:推送(push) vs 拉取(pull)?
短轮询:在客服端通过SetTimeout()/SetInterval()定时发送Ajax请求(又称之为定时轮询)
长轮询:在服务器端维持住一个HTTP请求,可以简单的理解为在服务器端SetTimeout()/SetInterval()
WebSocket:一种全新的Web双向通信协议,允许服务端主动向客户端推送数据
错误,可以细分为两种:bug和exception(复习)
无论哪种,都应该
后端的错误,如果是
#体会:为什么要防御式编程?尽可能的将逻辑性bug暴露出来#
Web项目中,对异常的处理,除了catch…log和finally…恢复以外,还涉及到:要给用户一个说法,究竟发生了啥事?体现为:
这里面一定要注意的是:
给你的飞机装上黑匣子。
让你的代码不再是玩具。
多快好省!前端后端,线上线下,名师精讲
更多了解 加:

