说明:
目标:查出所有Teacher。
CriteriaBuilder builder = em.getCriteriaBuilder(); CriteriaQuery<Student> criteria = builder.createQuery(Student.class); criteria.from(Student.class); TypedQuery<Student> query = em.createQuery(criteria); List<Student> students = query.getResultList(); students.forEach(s -> System.out.println(s.getName()));CriteriaBuilder:(仍然是builder模式)
CriteriaQuery<?>:
TypedQuery<X>:
EntityManager对象(这次不是CriteriaBuilder)的createQuery()方法,接受CriteriaQuery对象作为参数,以此构建TypedQuery<X>对象。
log演示:
getResultList():该方法才会利用之前生成的SQL语句,查询数据库。
调用CriteriaQuery的where方法,可以构建SQL语句的WHERE部分:
Root<Student> root = criteria.from(Student.class);
//设置条件:WHERE
//使用比较相等:equal
//比较的是Student的属性(attribute)name
//和"fg"进行比较
criteria.where(builder.equal(root.get("name"), "fg"));
转到定义演示:where要传入的是一个Expression(表达式),
本质是对查询条件的封装:
CriteriaQuery<T> where(Expression<Boolean> restriction);
public interface Expression<T> extends Selection<T> {
public interface Predicate extends Expression<Boolean> {
Expression实例又通过CriteriaBuilder的实例方法获得(这个有点……别扭?)
传入的是Expression,返回的还是Expression,所以可以连缀
#体会:强类型查询
同学们注意,这样用字符串给get()方法传递attributeName是很危险(error prone,容易犯错)的:
root.get("name")
道理不用多讲了吧?^_^
利用maven引入第三方组件jpamodelgen
演示:在项目上右键-properties,找到JPA下面的:
<dependency> <groupId>org.hibernate</groupId> <artifactId>hibernate-jpamodelgen</artifactId> <version>5.1.17.Final</version> </dependency>
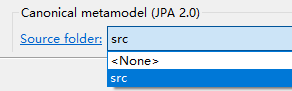
选择一个目录,apply and close。
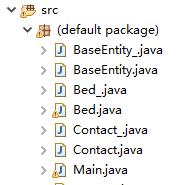
然后就会在src下面生成一系列的类,和entity同名但多一个下划线后缀:
@Generated(value="Dali", date="2021-10-21T20:56:15.279+0800")
@StaticMetamodel(Student.class)
public class Student_ extends Person_ {
public static volatile ListAttribute<Student, Score> scores;
public static volatile SingularAttribute<Student, Contact> contact;
背后原理:根据@Entity注解产生……,参考:
于是,我们就可以这样给get()方法传值:
root.get(Student_.name)
valueType的取值,使用get连缀
root.get(Student_.Contact).get(Contact_.city)
where()方法里面,除了可以equal(),还可以:
//大于,比较数值 builder.greaterThan(root.get(Student_.age), 17) //大于等于greaterThan-or-equal builder.ge(root.get(Student_.age), 17) //小于,比较时间(注意有类型编译时检查) builder.lessThan(root.get(Student_.enroll), LocalDate.now() //字符串like操作 builder.like(root.get(Student_.description), "%17bang%") //检查是不是NULL值 builder.isNull(root.get(Student_.rest)) //between builder.between(root.get(Student_.age), 20, 30)、 //在attribute(列)之间进行比较运算 builder.equal(root.get(Student_.age), root.get(Student_.id)) //对attribute(列)进行加工(转成大写)后运算 //不提倡,因为可能会索引失效,但确实没办法的时候…… builder.equal(builder.upper(root.get(Student_.name)),"ATAI")
当然,还可以把这些条件再通过not,and和or组合起来,比如:
criteria.where(builder.and( builder.not(builder.isNull(root.get(Student_.rest))), builder.or( builder.lessThan(root.get(Student_.enroll), LocalDate.now()), builder.like(root.get(Student_.description), "%17bang%"))));就问你舒服不舒服?
在实际开发中,我们通常会根据用户选择,动态地生成查询语句,这时候需要:
Predicate predicate = builder.isTrue(builder.literal(true));这个predicate不能直接赋值为null(原因见第3条),所以
if (true) {
predicate = builder.and(builder.isNull(root.get(Student_.rest)));
}
if (true) {
predicate = builder.or(predicate, builder.lessThan(root.get(Student_.enroll), LocalDate.now()));
}
if (true) {
predicate = builder.and(predicate, builder.like(root.get(Student_.description), "%17bang%"));
}
注意or()或and()里面的第一个参数predicate不能为null,所以一开始predicate不能直接设置为null(见第1条),否则有可能之前的分支没有走到,走到当前分支就直接报NullPointer异常。
criteria.where(predicate);
criteria.orderBy(new OrderImpl(root.get(Student_.age))); criteria.orderBy(builder.desc(root.get(Student_.age)));
还可以多列排序:
criteria.orderBy( builder.desc(root.get(Student_.age)), builder.asc(root.get(Student_.id)) );
排序之后取前三个呢?或者分页(跳过n个再取m个)呢?
TypedQuery<Student> query = em.createQuery(criteria) .setFirstResult(20) //从第20个开始取 .setMaxResults(10); //最多取10个
log演示生成SQL:order by student0_.age desc, student0_.id asc limit 20, 10
首先可以想到的是:查询的结果不能再是完整的entity了……
可以简单的使用Object[]指定查询结果类型:
CriteriaQuery<Object[]> criteria = builder.createQuery(Object[].class);
于是相应的:CriteriaQuery<Object[]>、TypedQuery<Object[]>、List<Object[]>都要发生更改。
但是,Root<Student>不用更改,因为它指示的是查询的起点,我们仍然是基于Student开始查询的。
criteria.multiselect( root.get(Student_.name), root.get(Student_.description) );
long演示生成的SQL:
select student0_.name as col_0_0_, student0_.description as col_1_0_ from Student student0_
就只查询了两列。
Object[]就只能通过下标来定位,表现力不够。
所以我们还是推荐使用javax.persistence.Tuple作为查询结果元素容器:
CriteriaQuery<Tuple> criteria = builder.createQuery(Tuple.class); //或者: //CriteriaQuery<Tuple> criteria = builder.createTupleQuery();
它最大的好处是可以强类型的使用
for (Tuple tuple : students) {
System.out.println(
tuple.get(0) + //可以用下标
":" +
//但建议用更有表现力的强力型变量
tuple.get(pDescription));
}
pDescription是为了重用,定义的变量:
Path<String> pDescription = root.get(Student_.description);
比如:成绩(Score)按科目(name)分组
首先要想到的,group的查询结果是典型的投影,因为拿到的结果应该是这个样子的:
|
科目 |
最好成绩 |
|
Java |
98 |
|
SQL |
96 |
|
CSharp |
96.5 |
Path<String> pName = root.get(Score_.name); //后面可以重用 //完成分组 criteria.groupBy(pName);
接下来就要使用multiselect,并指定分组过后的聚合运算:
//聚合运算函数count() Expression<Long> eCount = builder.count(pName); criteria.multiselect(pName, eCount);除了count(),还可以有:
Path<Float> pPoint = root.get(Score_.point);
甚至可以用builder构建差值(最好最差之间):diff()
criteria.multiselect(pName, builder.max(pPoint), builder.least(pPoint), builder.diff(builder.max(pPoint), builder.least(pPoint)) );
演示log生成SQL:select ……, max(score0_.point)-min(score0_.point) as col_1_0_
Path<String> pName = root.get(Score_.name); Expression<Float> eMin = builder.min(root.get(Score_.point)); criteria.groupBy(pName); criteria.multiselect(pName, eMin); criteria.having(builder.greaterThan(eMin, 90f));
演示log生成SQL:having min(score0_.point)>90.0
多快好省!前端后端,线上线下,名师精讲
更多了解 加:

