@想一想@:这样(面向数据库)开发舒服不舒服?
比如一次查询,你给我一个结果集,不看数据库我就不知道里面装的啥……能不能直接给我一个对象啊?对比:
//直接拿到Student对象
Student student = Student.getBy(98);
System.out.println(student.getName());
//拿到一个结果集
ResultSet student = Student.getBy(98);
System.out.println(student.getString("Name"));
从数据库取到的数据不会自动变成对象。所以,早期很多项目我们都要做这样的封装:
ResultSet rs = DriverManager.getConnection("").createStatement().executeQuery("SELECT *");
Student student = new Student();
student.name = rs.getString(1);
student.isMale = rs.getBoolean("isMale");
return student;
这样逐个逐个的手写代码的工作即乏味无趣又很容易出错。
略,都懂,^_^
我们发现,因为对象和数据库两者之间可以简单映射:
@想一想@:你能开发这样的工具么?用什么技术?
关键的关键,在于动态的(在运行时):
靠什么?当然就是反射。
Object Relationship-Database Map的首字母简写,对象关系数据库映射(工具),至少要能够实现上述两个基本功能(生成SQL语句&对象)
随着ORM的发展和普及,开发人员提出了更多的要求和期望,实现的有:
能够根据Java和C#的类(entity)生成数据库表结构,反之亦然
谁先谁后?
大多数情况下,类名和表名,属性名和列名,都是一一对应,都可以使用默认配置。但难免有一些非主流的要求,比如:
需要自定义的映射配置。早期用XML文件,现在一般用特性/注释或Lamda表达式
强烈建议先按暂停,自己想想,^_^。关键是要能够单独取父类对象哟。
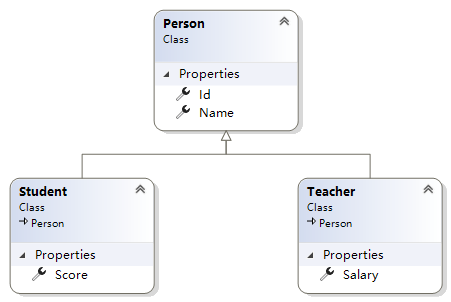
常见的策略有:
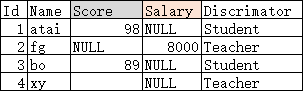
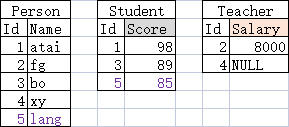

#常见面试题:该如何选择继承映射的策略呢?#
再次复习ORM的终极目的:忘掉数据库,只是持久化对象!
可以把ORM看成是Repository(复习)。我们的使用,就三个步骤:
@想一想@:第3步如何实现?同步不仅仅是UPDATE哟,还可能是INSERT(1是new出来的对象)和DELETE(2改的时候进行了删除)……
关键要知道加载到内存里的entity对象,究竟发生了什么变化。
怎么才能知道?按官方的说法,是记录entity的状态并进行追踪(track)。
状态一般包括:
有了状态,最后同步的时候就依据状态生成相应的Update/Delete/Insert语句。
PS:你可能好奇怎么追踪管理,^_^,方式多种多样,但最简单的就是比对:entity加载时就做一个快照(snapshot),持久化前再依次进行比较
但谁来做这事呢?不同的ORM有不同的称呼:
session一般翻译成会话,它是一个对象,首先能够封装和数据库的连接,能完成数据的存取操作。
还能够追踪/管理它所管辖的entity的状态(state)。
一个完整的会话:
状态追踪(track),贯穿session的整个生命周期。
假设某个session里(和快照相比)多了一个entity:
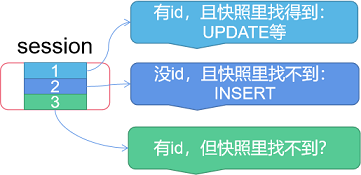
妙用:绕过load直接update。
前提:detached的entity还可以再attach到session中,受session管理追踪。
有时候我们可能希望能够直接删除/更改某个entity,常规的做法是先根据id将其load出来,然后再更改其属性或删除等,这样的话load就显得浪费。
如果是按上述逻辑定状态的ORM,我们就可以直接new一个entity,只给它的id赋值,再将其attach到某个session上,然后再进行预期的sync操作,这样就只有一次的SQL操作哟!^_^
上述操作,其实就是UoW(Unit Of Work,工作单元)的实现,只差最后一点点:
利用事务保证一个session里面所有的entity改动,作为一个整体同步到数据库,保证数据完整性和一致性。
ORM基本上都有对事务的支持,但和JDBC一样,实现依赖的是数据库,而且需要我们显式的开启,即:同步本身没有事务的效果。
实际开发中,entity对象之间存在着大量的、链式的、复杂的引用关系(复习:ER模型)
entity的引用关系映射到数据库,就是外键关系(复习)
比如Student关联(包含/引用/依赖)了Teacher,
public class Student {
public Teacher Teacher;
表结构就这样的:
|
Id |
Name |
TeacherId |
|
28 |
atai |
1 |
|
Id |
Name |
|
1 |
飞哥 |
我们需要事先统一/了解一些术语,以便接下来的学习。
描述entity之间的关系:
注意不要把这里的父类/子类和继承关系相混淆。
所以上述代码,Student是父类/主类,Teacher是子类/依赖类。
描述Entity类的内部成员:
int Age {get; set; }
Classroom StudyIn {get; set; }
IList<Teacher> Teachers {get; set; }
|
|
简称 |
定义 |
示例(当前entity:Studnet) |
|
关联属性 |
|
对另一个@Entity的引用 |
Student taughtBy |
|
关联集合 |
集合 |
对其他entites集合的引用 |
Set<Student> teachers |
|
基本属性 |
属性 |
Java基本类型+String+时间类型等 |
int age、String name |
|
ValueType |
|
对另一个@embedable的引用 |
Contact contact |
新增一个对象时,将其关联属性/集合也持久化:一般来说都没啥问题。只是在一对多关系的时候,有两种策略:
Student atai = new Student(); //INSERT Student
atai.Teacher = new Teacher("fg"); //INSERT Teacher
session.save(atai);
//@想一想@:哪一个INSERT先执行?
删除一个entity的时候,
如果entity是父类,会产生级联删除(复习),需要指示:
Teacher fg = session.load(1); session.remove(fg); //fg的学生怎么办? //1. ORM只生成并执行DELETE Teacher,Student表的处理由数据库负责 //2. ORM生成DELETE Student 或者 UPDATE Student的语句并首先执行,最后才DELETE Teacher
最复杂的是关联对象的加载:(当然也可以完全不加载,就给个TeacherId,你要这个Teacher的其他属性,自己再去查……:但这样就不面向对象了,累赘,不够智能)
Teacher fg = session.load(1); //students从哪里来?怎么来? List<Student> students = fg.getStudents(); //null?
//这时候就一次性的查询Teacher和Student两张表 //SELECT * FROM Teacher JOIN Student ON…… Teacher fg = session.load(1);
但很多时候,entity之间的关联特别复杂:
如果说这些关联对象都要一次性的取出,很容易在session中加载大量entity,耗尽系统内存资源。关键是,这些关联对象有可能还用不到。
所以通常都需要具体的指定要加载哪些关联对象出来:
Teacher fg = session.load(1) //这样指明只加载Students,其他关联entity不加载 .include(t->t.getStudents());
但是,这种方式的问题是:适用性不够。比如我们将其封装成一个方法:
static Teacher getById() {
return session.load(1)
.include(t->t.getStudents());
}
这个方法就定死了只能加载出Students,其他关联entity没有加载。但方法是要被到处调用的:
Teacher fg = getById(1);
Explicit Load:取得entity之后
Teacher fg = session.load(1) //SELECT * FROM Teacher WHERE id = 1
再就entity需要关联的对象进行声明加载
session.include(fg, f->f.getStudents()); //SELECT * FROM Student WHERE StudentId = 1
这样解决了eager load的适用性问题,但会产生多次查询,而且显得麻烦……
deferred load,又被称之为惰性/懒惰加载(lazy load)。
应用开发人员(ORM使用者)可以假定 所有的关联对象都是已经load出来的(但实际上并没有),然而一旦我们要使用某个关联entity的时候,ORM会自动的查询数据库获取数据,填充该关联entity。神奇不?^_^
Lazyload通常是通过proxy模式实现的:
但有可能带来1+n的性能问题:
List<Student> students = session.load(1).getStudents(); //这是1
for (Student student : students) { //这是n
//每一次都会进行数据库查询
System.out.println(student.getName());
}
没有一个加载模式是完美的,ORM一般提供了几种加载关联数据的模式,供开发人员选择。
我个人的偏好:
Entity中一些类,并不需要被映射成单独的表。
因为他们没有独立存在价值,总是“依附”于其他entity而存在。典型的比如Address,业务逻辑绝不会单独的查“某一个”地址,而是查找一个用户,用户就有一个地址……
所以Address不需要主键,只需要在User表里给它几个列就可以了。
在Hibernate中被称之为Component,JPA中称之为ValueType, EF中被称之为Owned Entity……
其实质相当于,把多个普通“相关属性”
public class Student : Person
{
public string BedLocation { get; set; }
public int BedSize { get; set; }
合并成一个类:
public class Student : Person
{
public virtual Bed Bed { get; internal set; }
public class Bed
{
public string Location { get;set; }
public int Size { get; set; }
很多时候,可以代替1:1映射。
新建一个ORM项目
根据一起帮的功能构建相应的entities/value types并自动映射生成相应的表,并插入数据。包括但不限于:
删除一个文章系列,保留该系列所有文章,并将其移动到另一个文章系列下。
新建User类,将User类映射到数据库:
多快好省!前端后端,线上线下,名师精讲
更多了解 加:

