其实就是用Java/C#,连接数据库,进行增删改查的操作。
所谓持久化,建立在以下逻辑基础上:
体现的这样的思想:应该面向对象(或者领域),而不是面向数据库
PS:DDD(Domain Design Driven),领域驱动。
和发送Email一样,底层的东西我们其实不用操心(比如:JVM和CLR怎么就连接上数据库的),我们只需要学会调用类库就OK了。
这些类库使用共同的接口,这一系列的接口集被称之为:
这些接口又被称之为API(复习:所谓API),以上API都是语言标准库自带的。
但接口没有实现,不能运行,所以还需要驱动(driver,实现了这些接口的类库,dll或jar)
驱动由数据库厂商(官方)/第三方提供。
@想一想@:为什么要这样做?(多态)
所有对数据库的操作,其实都可以抽象/概括成:
#常见面试题:JDBC/ADO.NET的n大对象是?#
连接到数据库,通常需要连接字符串,包含:
不同的驱动连不同的数据库,有不同的格式要求:
Data Source=数据库地址;Initial Catalog=数据库名称;User Id=数据库登录名;Password=数据库密码;
jdbc:mysql://数据库地址:端口号/数据库?user=用户名&password=密码
实际开发中,连接字符串
注意:上述1和2是矛盾的。所以需要根据具体情况选择合适的策略(Web开发中常用的是ConnectionPerRequest)
一些常见错误:
作用同字符串池和线程池。
.NET内置了连接池,Java需要自己选择配置。
增删改查都是由包含SQL语句的Command/Statement对象实现的:
早期开发人员会将用户输入和SQL语句拼接成字符串,之后进行查询,会造成SQL注入的问题。
比如实现准备好这么一条语句:
UPDATE Student SET Enroll = '2020/5/29' WHERE [Name] = '{name}'
然后用用户输入值代替{name},我们期待的是用户输入学生的姓名,比如:atai,这是OK的。
但恶意用户想得更多,……,比如他想利用这个机制删除整张表!怎么办?
只需要做成这样的SQL语句就OK了:

高亮部分就是用户的输入。(演示:删除一行)
@想一想@:假设你是一个恶意用户,想绕过用户名密码检查登录一起帮,你该怎么做?假设后台用到的SQL语句是:
SELECT COUNT(*) FROM [User] WHERE [Name] = N'{name}'AND Password = N'{password}'
参考答案:fg' OR 1=1 --
早期开发人员会在拼接字符串之前做一些验证,过滤恶意输入。
但现在主流的办法是直接使用:参数化SQL语句
其核心就是:
使用参数化查询,上述SQL代码会变成:
UPDATE Student SET Enroll = '2020/5/29' WHERE [Name] = @name
为了便于理解,同学们可以将其“想象成”这样的SQL执行方式:
DECLARE @name NVARCHAR = N'飞哥;DELETE Student';
UPDATE Student SET Enroll = '{DateTime.Now}' WHERE [Name] = @name;
理解:用户的输入无法变成可执行的SQL语句。
有时候,我们可能需要一次性的执行多条SQL语句(比如:标记已读/删除消息通知)。
即使是在同一个连接里面,SQL语句一条一条的执行,一行一行的更新/删除,可能(不是肯定!需要测试)不如一次性的执行效率高。
所以,JDBC和ADO.NET有点绕都提供了批(batch)处理的执行方式:
分两种:
如果是(单个元素的)标量,可以直接转换成Java/C#类型。
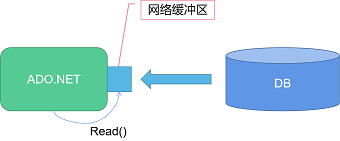
如果是(表结构的)结果集,就会用一个特殊对象(JDBC:ResultSet / ADO.NET:DataReader)来存放,要求可以:
注意结果集的读取,需要保持和数据库的连接。换言之,结果集对象并不是一个真正存放了查询结构的数据容器,而是一个能够获取数据库数据的工具。
我们可以想象这样一种常见的场景(基于性能优化等原因考虑):
注意:
多快好省!前端后端,线上线下,名师精讲
更多了解 加:

